Pytorch Tutorial¶
PyTorch 是一个基于 Python 的机器学习框架,其两大核心功能是:支持在 GPU 上进行高效的 N 维张量(Tensor)计算(类似 NumPy),以及提供用于训练深度神经网络的自动微分(Automatic Differentiation)机制。
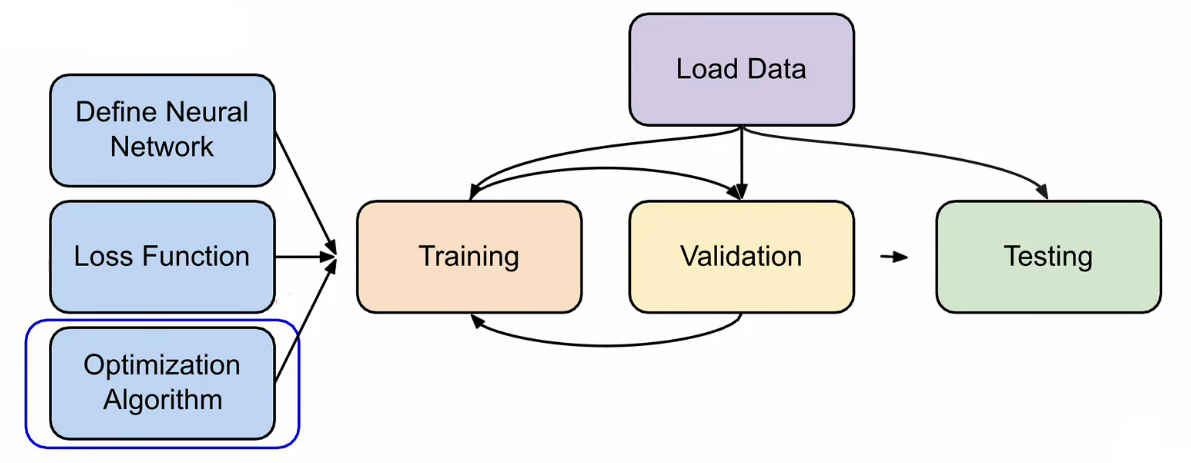
Load data¶
在 PyTorch 中训练和测试神经网络的第一步是加载数据,主要通过 torch.utils.data.Dataset 定义数据集、torch.utils.data.DataLoader 实现数据分批与打乱;
在 PyTorch 中
Dataset用于存储数据样本及其对应的标签(期望值)DataLoader则负责将数据集按批次(batch)分组、支持多进程加载以提升效率;
使用时先通过自定义类如 MyDataset(file) 创建 dataset 对象,再传入 DataLoader(dataset, batch_size, shuffle=True) 构建数据加载器——其中 shuffle=True 通常在训练阶段启用以打乱数据顺序,而在测试阶段设为 False 以保证评估一致性。
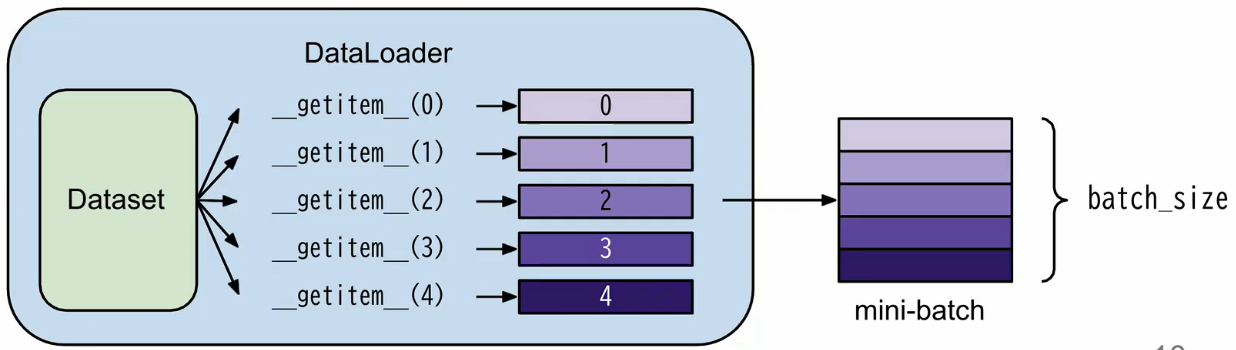
采用这个架构的原因是可以不受内存大小的限制。如果数据集非常大的话,如果单纯的只有一个数据集的话,那么一开始数据都要放到内存中去,而有这样的 loader,我就可以从硬盘中取了。
Data 对象如何定义
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, file):
# Read data & preprocess
self.data = ... # 在此处加载并预处理数据
def __getitem__(self, index):
# Returns one sample at a time
return self.data[index] # 返回单个样本(如图像+标签)
def __len__(self):
# Returns the size of the dataset
return len(self.data) # 返回数据集总样本数
Tensors¶
Tensors 是高维的矩阵(数组)
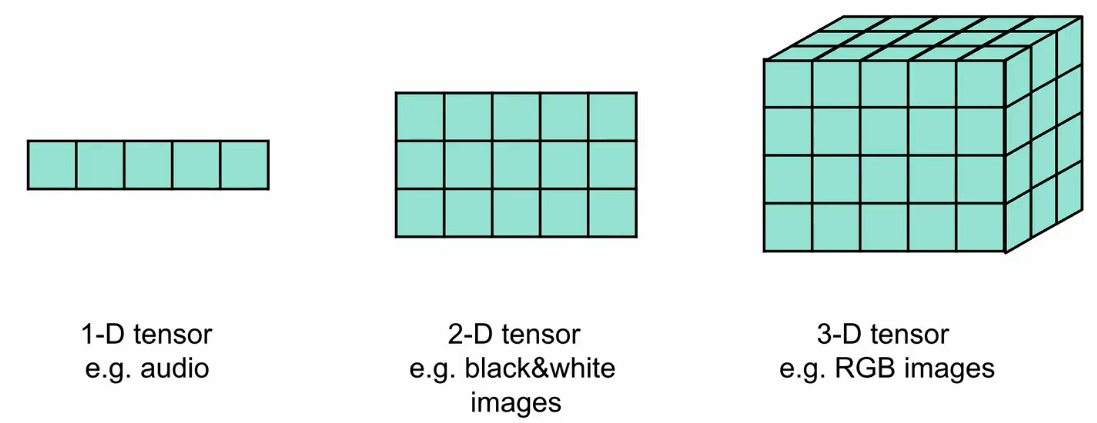
Tensor 的 shape 返回的就是这个矩阵的形状
比如说第一个 tensor 的形状就是 (5,)第二个是(3,5)
PyTorch 创建张量主要有两种方式:
- 从现有数据(列表或 NumPy 数组)直接构造,如
torch.tensor()或torch.from_numpy();
x = torch.tensor([[1, -1], [-1, 1]]) x = torch.from_numpy(np.array([[1,-1], [-1,1]]))
- 按形状初始化常量张量,如
torch.zeros(shape)和torch.ones(shape),其中shape是维度元组。
x = torch.zeros([2, 2]) x = torch.ones([1, 2, 5])
常见的 tensor 运算
- 加减幂:
z = x + y,z = x - y,y = x.pow(2) - 聚合操作:
y = x.sum()(求和),y = x.mean()(均值)
做加减运算的时候,要求形状要一样
- 张量转置(Transpose)
x = torch.zeros([2, 3]) # 创建形状为 [2, 3] 的张量
>>> x.shape
torch.Size([2, 3])
>>> x = x.transpose(0, 1) # 交换第0维和第1维
>>> x.shape
torch.Size([3, 2]) # 形状变为 [3, 2]
- 张量压缩(Squeeze)和扩展(unsqueeze)
>>> x = torch.zeros([1, 2, 3]) # 形状: [1, 2, 3]
>>> x.shape
torch.Size([1, 2, 3])
>>> x = x.squeeze(0) # 移除第0维(长度为1)
>>> x.shape
torch.Size([2, 3]) # 新形状: [2, 3]
>>> x = torch.zeros([2, 3]) # 形状: [2, 3] (二维)
>>> x.shape
torch.Size([2, 3])
>>> x = x.unsqueeze(0) # 在第0维前插入新维度
>>> x.shape
torch.Size([1, 2, 3]) # 新形状: [1, 2, 3] (三维)
- 张量拼接(Cat):沿指定维度将多个张量首尾相连,合并为一个更大的张量
>>> x = torch.zeros([2, 1, 3]) # 形状: [2, 1, 3]
>>> y = torch.zeros([2, 3, 3]) # 形状: [2, 3, 3]
>>> z = torch.zeros([2, 2, 3]) # 形状: [2, 2, 3]
>>> w = torch.cat([x, y, z], dim=1) # 沿第1维(中间维度)拼接
>>> w.shape
torch.Size([2, 6, 3]) # 新形状: [2, 6, 3] (1+3+2=6)
- 张量梯度计算(Gradient Calculation):通过自动微分机制,计算标量输出对输入张量的梯度。
>>> x = torch.tensor([[1., 0.], [-1., 1.]], requires_grad=True) # 设置 requires_grad=True 以启用梯度追踪。
>>> z = x.pow(2).sum()
>>> z.backward()
>>> x.grad
tensor([[ 2., 0.],
[-2., 2.]])
- 张量数据类型(Data Type):模型与输入数据必须使用一致的数据类型,否则将引发运行时错误。
| 数据类型 | dtype |
对应 Tensor 类型 |
|---|---|---|
| 32-bit 浮点数 | torch.float |
torch.FloatTensor |
| 64-bit 有符号整数 | torch.long |
torch.LongTensor |
张量和模型默认在 CPU 上计算;若需加速,可手动移至 GPU(CUDA)。
用 .to(device) 方法将张量或模型移动到指定设备:
使用 torch.cuda.is_available() 判断当前环境是否有可用的 NVIDIA GPU:
How to define a NN?¶
Layers¶
如何使用 Pytorch 来定义一个神经网络呢?使用 torch.nn.module 这个库
nn.Linear(in_features, out_features) 定义的是一个全连接层
in_features:输入特征的维度(即每个样本的特征数)out_features:输出特征的维度(即该层神经元个数)
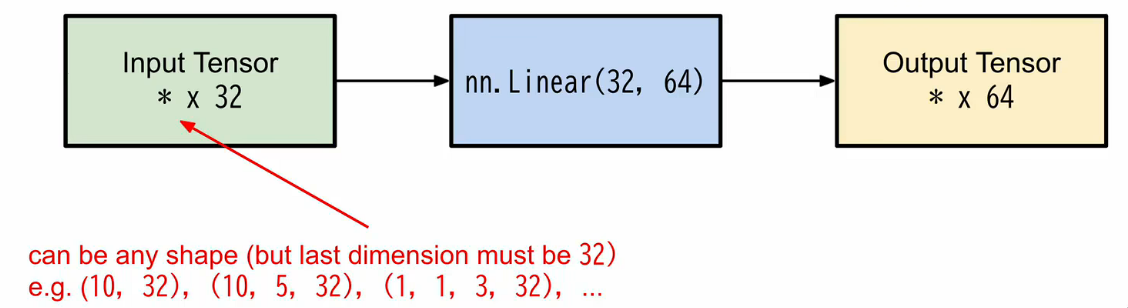
这个实现的是一个全连接的线性层
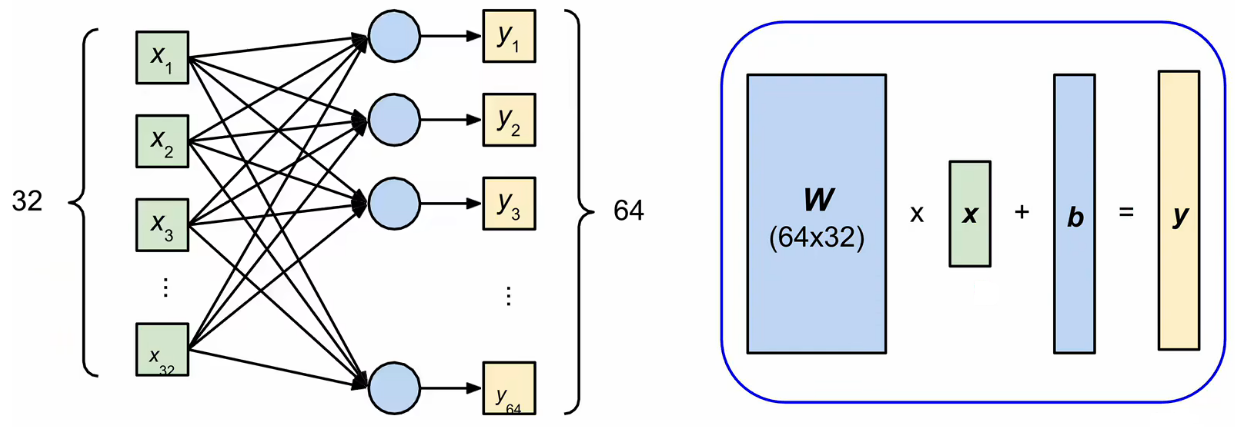
如何检查 linear 层的各个参数呢
>>> layer = torch.nn.Linear(32,64)
>>> layer.weight.shape
torch.Size([64,32])
>>>layer.bias.shape
torch.Size([64])
nn 里面也有一些非线性层
Construction¶
那么我们怎么利用 nn 库来构建神经网络呢?
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__() # 初始化模型并定义层
self.net = nn.Sequential(
nn.Linear(10, 32), # 输入10维 → 输出32维
nn.Sigmoid(), # 激活函数
nn.Linear(32, 1) # 输入32维 → 输出1维(如二分类)
)
def forward(self, x):
return self.net(x) # 计算神经网络输出
也可以选择如下构建
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定义网络层
self.layer1 = nn.Linear(10, 32) # 输入10维 → 输出32维
self.layer2 = nn.Sigmoid() # 激活函数
self.layer3 = nn.Linear(32, 1) # 输入32维 → 输出1维
def forward(self, x):
# 前向传播:逐层计算
out = self.layer1(x) # 第一层线性变换
out = self.layer2(out) # 第二层激活函数
out = self.layer3(out) # 第三层线性变换
return out # 返回最终输出
Loss Funcions¶
对于 Loss Functions,我们也可以使用 nn 这个库来做
损失函数根据任务类型选择:
-
回归任务使用
nn.MSELoss() -
分类任务使用
nn.CrossEntropyLoss();
两者调用方式统一为 loss = criterion(model_output, target)
Optimize¶
得到 Loss 之后就需要去 optimize 了,使用什么样的优化策略需要定义
比如说采用 Stochasitic Gradient Descent (SGD) 使用方法:先创建优化器(如 optimizer = torch.optim.SGD(model.parameters(), lr, momentum=0)),然后对每个数据批次执行三步
optimizer.zero_grad()清空梯度;loss.backward()反向传播计算梯度;optimizer.step()更新参数。
Training¶
综合来说,一个简单的训练过程如下
准备阶段:
# 1. 加载数据
dataset = MyDataset(file)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True)
# 2. 构建模型并移至设备(CPU/GPU)
model = MyModel().to(device)
# 3. 定义损失函数与优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
训练循环:
for epoch in range(n_epochs):
model.train() # 设置模型为训练模式
for x, y in train_loader:
optimizer.zero_grad() # 清空梯度
x, y = x.to(device), y.to(device) # 数据移至设备
pred = model(x) # 前向传播
loss = criterion(pred, y) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
验证循环:
model.eval() # 设置模型为评估模式(关闭 Dropout/BatchNorm 等训练层)
total_loss = 0
with torch.no_grad(): # 禁用梯度计算,节省内存 & 加速
for x, y in val_loader:
x, y = x.to(device), y.to(device) # 数据移至设备
pred = model(x) # 前向传播
loss = criterion(pred, y) # 计算损失
total_loss += loss.cpu().item() * len(x) # 累加加权损失
avg_loss = total_loss / len(val_dataset) # 计算平均损失
测试循环:
model.eval() # 设置模型为评估模式(关闭 Dropout/BatchNorm 等训练层)
preds = []
with torch.no_grad(): # 禁用梯度计算,节省内存 & 加速
for x in tt_set: # 遍历测试数据集或 DataLoader
x = x.to(device) # 数据移至设备
pred = model(x) # 前向传播
preds.append(pred.cpu()) # 收集预测结果(转回 CPU)
对于训练好的或者说中间的模型,如何保存和加载呢?
- 保存模型
- 加载模型
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!