9 Video & Audio Generation¶
之前我们处理的都是文字的信息,这一节中我们要处理的是输入文字,输出图片,语音,影片。
一个最基本的想法是将影像拆解为最小的单位(像素),把声音拆解为取样点,然后像预测下一个像素或者取样点
- 影像生成 = 像素接龙:早期的研究如 Pixel RNN 和 Pixel CNN 就是尝试这样做的。它们根据已有的像素作为“上下文”(Context),去预测下一个像素是什么。
- 影片生成 = 一张一张图片接龙:同理,影片就是一连串的图片。Video Pixel Networks 就是基于这个思路,先生成第一张图,再生成第二张,依此类推。
然而,这种做法存在一个根本性的问题。就像虽然万物由原子构成,但我们通常说细胞是构成人体的基本单位一样,直接对像素或原始声音取样点进行“接龙”,效率低下且难以捕捉高层次的语义信息。
离散型¶
为了解决这个问题,研究者们引入了“Token”的概念。Token不是原始的像素或取样点,而是经过编码后、具有语义信息的、离散的表示。
那么如何找出Token? 主要技术是 VQ-VAE。它包含一个编码器(Encoder)和一个解码器(Decoder)。编码器将输入的图像/声音压缩成一个更小的特征图,然后在一个预先定义好的 Codebook 里,找到最接近的向量,对原先解析出来的连续潜空间进行离散化。解码器则负责将这些Token还原成原始的影像或声音。然后更新 Codebook 得到 Token。
当然 VQ-VAE 也有相应的问题,VQ-VAE 使用一个单一码本(codebook)对编码器输出进行量化。然而,当希望提升重建质量(即降低量化误差)时,通常需要:
- 增大码本大小(例如从 K=512 增加到 K=8192 )
- 提高每个向量的比特率(bitrate)
这样会导致码本规模爆炸。一个解决方法是 Residual Vector Quantization (RVQ),核心思想是每一层量化器只负责量化前一层的残差。
设原始连续潜在向量为 \(z∈\mathbf{R}^d\) 。
- 第 1 层:用码本 \(C_1 = \{e_1^{(1)}, \dots, e_K^{(1)}\}\) 对 \(z\) 进行量化,得到量化结果 $ q_1 $,残差为
- 第 2 层:用另一个独立码本 \(C_2\) 对 \(r_1\) 量化,得到 \(q_2\),新残差为
- 第 \(n\) 层:依此类推,直到第 \(N\) 层。 最终的量化表示为所有层级量化向量的叠加:
其中,每个 \(q_i\) 来自第 \(i\) 个码本中的某个嵌入向量。
这样的还原层数越多,还原的精度越高。SoundStream、EnCodec、Mimi 等模型都使用了这种方法。
我们将图像和语音 Token 化之后,我们就可以直接使用为文字设计的 Transformer 模型来进行“接龙”!然后对接出来的 token 进行 detokenization 即可。
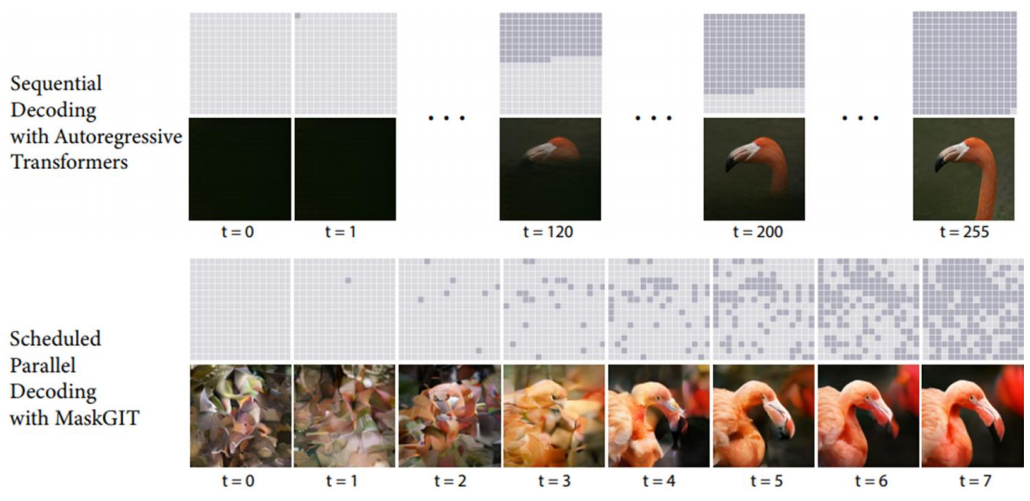
传统的文字接龙是严格从左到右(或从上到下)的,但这不符合人类绘画的方式。于是,新的接龙策略被提出,其中一个方法是 MaskGIT,这个方法的思路是首先用 VQ-VAE 把图像转成离散的 token 序列,然后训练一个类似 BERT 的双向 Transformer,学会根据部分可见的 token 预测被掩码([MASK])的位置。
具体来说训练过程完全模仿 BERT:
- 对真实图像的 token 序列 zz ,随机掩码一定比例(如 40%)的 token,替换为
[MASK]。 - 将掩码后的序列 \(\tilde{z}\) 输入 Transformer。
- 损失函数为:仅对被掩码位置计算交叉熵损失,目标是恢复原始 token
最后生成阶段是一步一步生成 token,一开始输入的是全为 [MASK] 的序列(长度 \(N\) )每一步迭代的过程如下:
- 并行预测:模型对所有
[MASK]位置输出 token 概率。 - 置信度选择:根据预测概率(如 softmax 最大值)计算每个位置的置信度。
- 部分填充:只将最可信的若干 token 替换为预测值,其余仍保留
[MASK]。 - 重复:用新序列作为下一轮输入,直到无
[MASK]剩余。
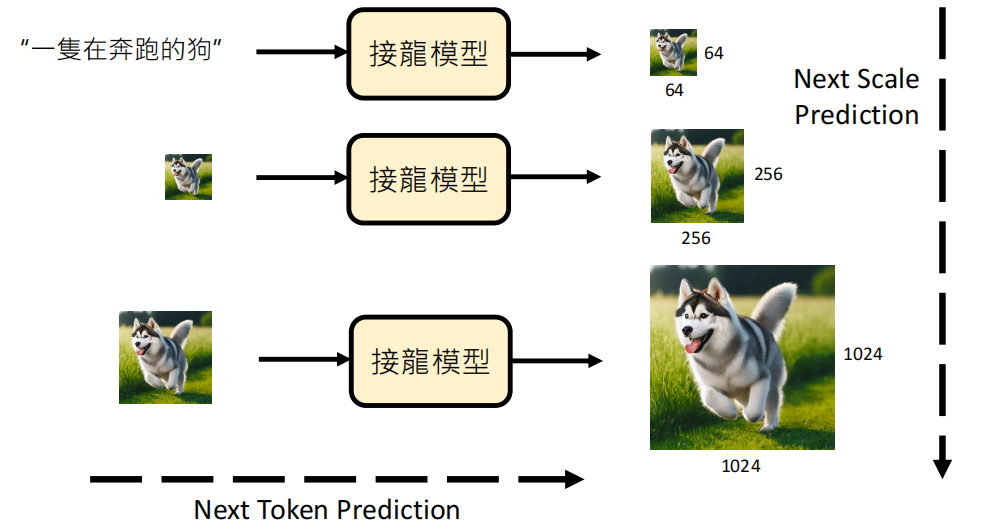
还有一种思路是多尺度(Multi-Scale)生成,首先生成一张低分辨率的完整图像(例如 64×64),作为整体结构的“草稿”;随后,以此草稿为引导,逐步生成更高分辨率(如 256×256)的细节内容;这一过程可迭代进行,逐级提升分辨率,直至达到目标尺寸(如 1024×1024),从而实现从粗略构图到精细纹理的渐进式图像生成。
连续型¶
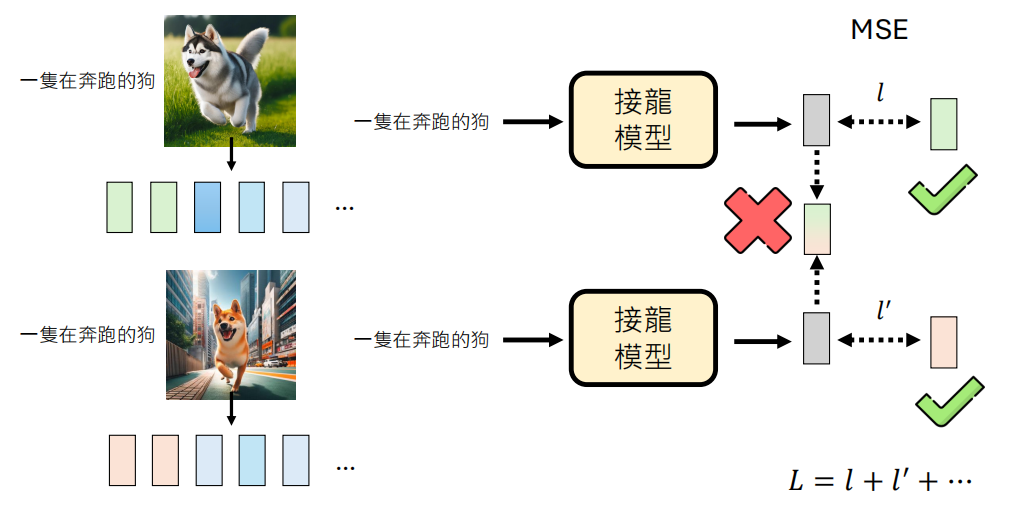
上述方法的核心思想就是将图片用一个一个的 token 来表示,本质上来说就是一个压缩的过程,总会损失掉一些信息的,所以不管这个接龙模型再怎么好,token 表示的不准确性极大的限制了图像生成的品质。
那么我们可以考虑使用连续型的 tokens 来表示,但是这就引出了一个新的问题就是:如何定义损失函数?
对于文字,模型输出的是词表中每个词的概率,可以用交叉熵损失。但对于连续的数值,如果用简单的均方误差(MSE),生成的图像会非常模糊,因为MSE鼓励模型取所有可能性的“平均”,而不是做出清晰的选择。
此时我们可以不让模型产生具体的数值(即 token 的值),而是输出一个概率分布的参数(比如高斯分布的均值和方差),然后从这个分布中采样得到最终的输出。
常用的方法有 VAE, GAN, Diffusion, Flow 等等,其中关于扩散模型 VAE 的细节在 Hugging Face Diffusion Models Course 有详细的阐述,这里我们讨论一下 Flow Matching 的基本思想。
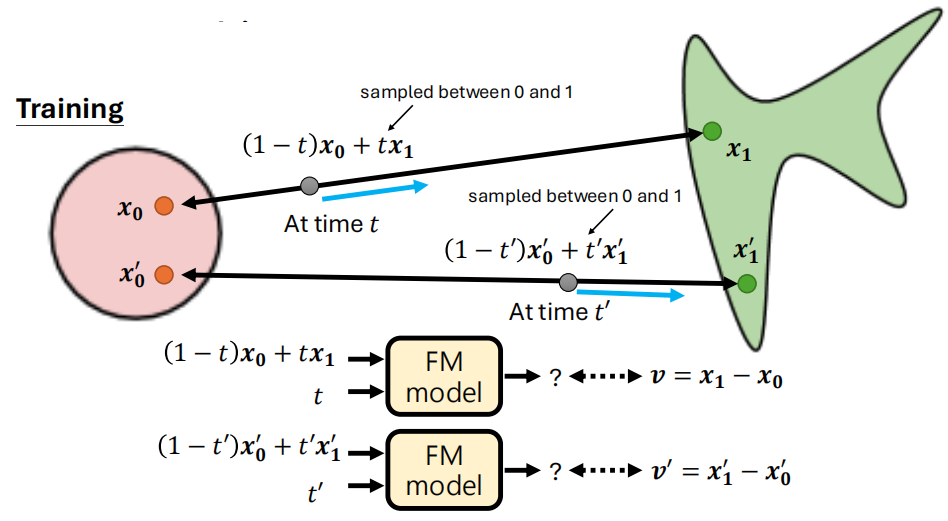
Flow Matching 希望通过学习一个 vector field,引导数据点从一个简单的先验分布(如高斯噪声)沿着一条平滑、确定性的路径流动到复杂的数据分布(如图像)
- 起点:在时间 \(t=0\) ,所有样本服从一个简单分布(如标准高斯分布 \(p_0(x)=\mathcal{N}(0,I)\))。
- 终点:在时间 \(t=1\) ,样本应服从真实数据分布 \(p_1(x)\) (如自然图像)。
Flow Matching 将这一演化过程建模为一个常微分方程(ODE):
其中:
- \(x(t)\) 是粒子在时间 \(t\) 的位置;
- \(v_θ(x,t)\) 是一个由神经网络参数化的速度场(或称向量场),它决定了粒子在每一点的运动方向和速度。
给定初始点 \(x(0)∼p_0\) ,通过求解该 ODE,可得到终点 \(x(1)\) ,理想情况下 \(x(1)∼p_1\) 。
所以问题的关键在于如何训练 \(v_{\theta}\) ,Flow Matching 不直接优化似然,而是采用一种局部匹配策略:
- 对任意真实数据点 \(x_1 \sim p_1\),人为构造一条从噪声到 \(x_1\) 的参考路径(例如线性插值):
-
沿着这条路径,可以计算出真实的瞬时速度(如线性路径的速度就是 \(x_1 - x_0\))。
-
神经网络的目标是:在任意时间 \(t\) 和位置 \(x(t)\) 上,预测的速度 \(v_\theta(x(t), t)\) 尽可能接近真实速度。
损失函数通常为:
其中 \(u_t\) 是参考路径的真实速度。
两种方法的汇聚¶
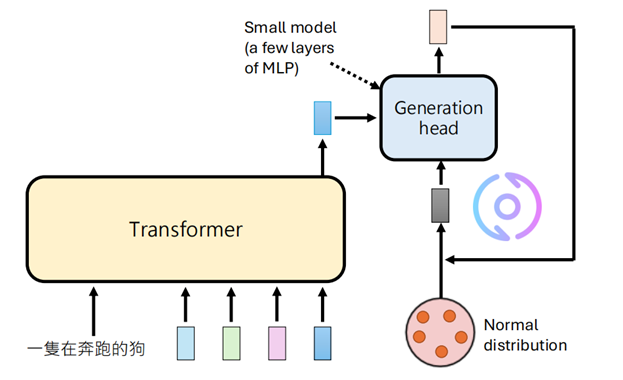
transformer 比较擅长处理序列和上下文,而 diffusion/flow head 擅长处理连续数值分布,我们将两者进行结合。首先由 Transformer 输出根据上下文信息得到的条件信息,代表了 Transformer 对下一个 token 长什么样的理解,然后将其作为指导信号输入到 generation head 中生成相应的连续型 token
其实就是将之前查表的步骤用一个小型的神经网络(Generation head)进行了替换。
相比于传统的 diffusion/flow 方法,通常需要 20~50 步(甚至更多)的迭代去噪才能生成一张高质量图片。因为它必须从纯高斯噪声(随机乱码)开始,一步步“猜”出整张图的结构。
而在这里Transformer 承担了“构图”的工作:
- Transformer 通过自回归的方式,已经通过上下文“推理”出了图片的大致结构和语义。
- Generation Head 只做“细化”:Head 只需要负责把 Transformer 给出的模糊特征转化为具体的像素细节。
Generation Head 往往只需要 1~4 步 就能完成生成。因为起点已经不是纯噪声,而是被 Transformer 高度约束过的状态。
同时这里 transformer 部分可以无缝地应用各种自回归的技巧,如使用 MaskGIT 的并行解码策略,可以极大地提升生成速度。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!