2 Context Engineering¶
模型本身参数无法随意更改(那是训练阶段的事),人类能做的只有优化输入。通过精心管理和设计输入给模型的“上下文(Context)”,让模型在有限的能力下发挥最大效能。
Context Engineering & Prompt Engineering
概念基本是类似的,有一点点区别
- Prompt Engineering:关注单次输入的格式和“神奇咒语”。
“神奇咒语” 比如说加入 “你回答好一些我就给你小费”等等,但是这些咒语随着模型能力的增强,这些咒语显得越来越没用
- Context Engineering:关注整个对话生命周期的信息管理,包括长期记忆、工具使用记录、多轮对话历史等,是一个自动化、动态的管理过程。
Inside Context¶
User Prompt (用户提示):是用户直接给予的指令。值得注意的是其中前提与范例对于大模型回答质量的显著影响作用。
- 提供前提:比如说,666 是什么意思?在不同地区意义并不相同,回答的结果可能不是你想要的,但是给他相应的前提,比如说在中国,那就会回答比较好的答案
- 提供范例:比如说要求英翻法的时候,前面给几个例子,效果会好很多。这个也被称为 In-context Learning,当然这里的学习并不是真正的学习,因为并没有改变模型的参数。
System Prompt (系统提示)这是预先设定好的隐藏指令,用于定义模型的基础行为与边界。有些模型的 system prompt 是公开出来的,比如说 claude 的 system prompt
System Prompt 通常包含
- 基本身份与产品信息:模型是谁、由谁开发。
- 使用说明与限制:引导模型如何回答特定问题(如 API 相关问题)。
- 互动态度与用户反馈:规定模型对用户不满时的反应。
- 安全与禁止事项:列出不能生成的内容(如制造武器信息)。
- 回应风格与格式:规范输出的固定格式或禁忌词。
- 知识与事实性:声明知识截止时间,避免胡编乱造。
- 自我定位与哲学原则:如不宣称拥有人类意识。
- 错误处理与互动细节:规定被纠正时的思考与回应流程。
Dialogue History (对话历史 / 短期记忆):记录当前会话中用户与模型过往的问答内容。这构成了模型的“短期记忆”,让模型能理解当前的对话脉络,但这些内容并未用来训练模型参数。开放新对话后,这些记忆就会消失。
Long-term Memory (长期记忆):来自其他数据源的相关信息,超越单一对话窗口的限制。通常通过 RAG (检索增强生成) 技术,从网络、数据库或外部文件中检索并注入相关信息,以补充模型知识库的不足。
Tool Use (工具使用信息):当任务超出模型纯文本能力时,Context 需包含可用工具的说明与调用格式。
- 工具定义:列出可用的函数(如查询天气
Temperature(location, time))。 - 执行指令:模型生成的工具调用代码(如
<tool>Temperature(...)</tool>)。 - 工具输出:工具执行后的结果(如
<output>摄氏 32 度</output>),这些结果会被放回 Context 供模型生成最终回答。
Computer Use:甚至包含屏幕画面截图与鼠标/键盘操作指令,让模型能操控电脑。
Reasoning (模型思考过程):针对复杂任务,模型内部产生的“脑内小剧场”。包含规划、尝试不同解法、验证结果的过程(例如:“先看 A 解法...不对,再试 B 解法...好像是对的”)。这段过程通常对用户隐藏,但存在于 Context 中以辅助最终答案的生成。
由于上述内容累积起来会非常长,而模型存在“迷失在中间 (Lost in the Middle)”或“上下文腐烂 (Context Rot)”的问题,因此需要通过 Context Engineering 技术(如筛选、压缩、多智能体分工)来管理这些内容,避免塞爆 Context 导致效能下降。
Why Context Engineering?¶
AI Agent
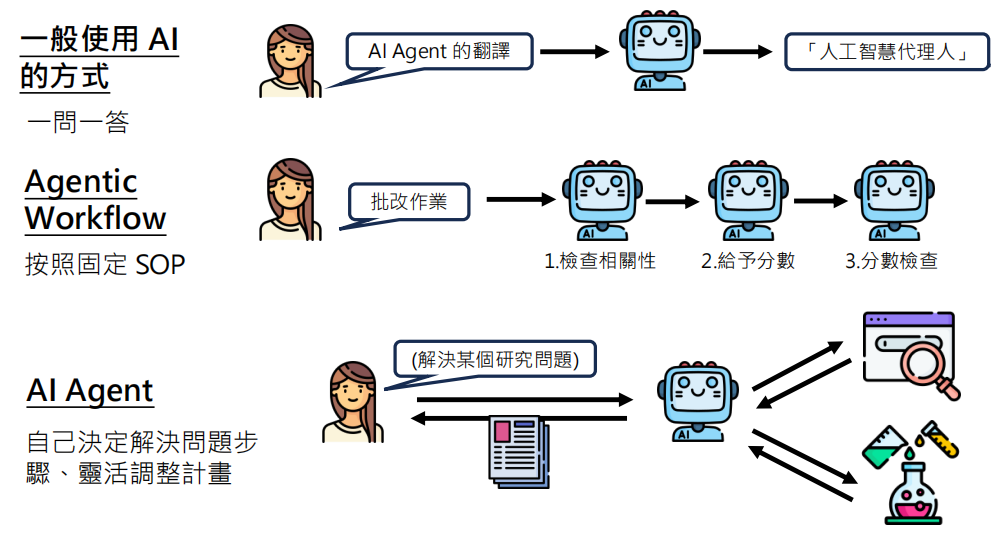
下面是 AI agent 的一个基本过程:
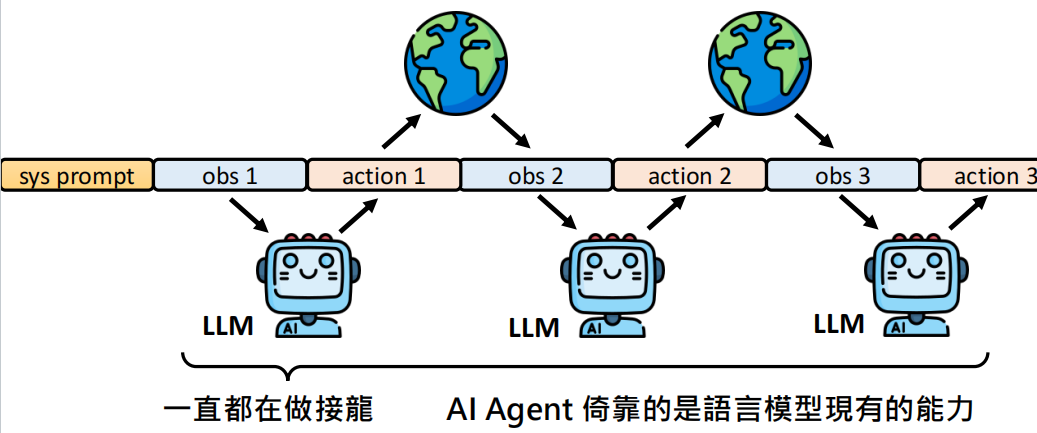
AI Agent 做的其实就是一个文字接龙的过程。利用当前得到的观察,做出相应的动作,然后有了新的对世界的观察,继续做出相应的动作,一直这么下去即可。
那么一个挑战就是 context 输入过长,会导致 LLM 的回答出现问题。
RAG:搜寻到的资料越多越好吗?
随着资料的增多,效果先变好后变差。
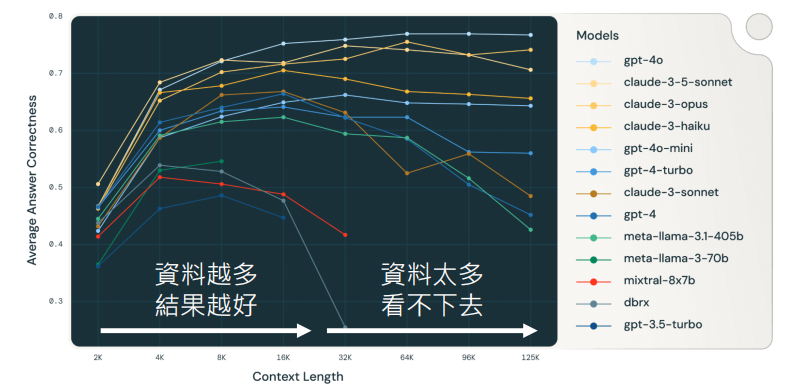
迷失中间 (Lost in the Middle):模型对开头和结尾的信息记忆较好,但容易忽略中间海量的细节。
上下文腐烂 (Context Rot):输入越长,模型性能反而下降,甚至无法理解关键指令。
信息噪音:并非所有历史信息都有用。例如:操作电脑时的琐碎鼠标移动、失败的尝试步骤、过期的临时数据,如果全部塞给模型,会干扰其判断。
Context Engineering 的基本方法¶
核心原则:把需要的放进去,不需要的清出来。
Select¶
不要把所有东西都塞进 Context,而是像搜索引擎一样“按需索取”。
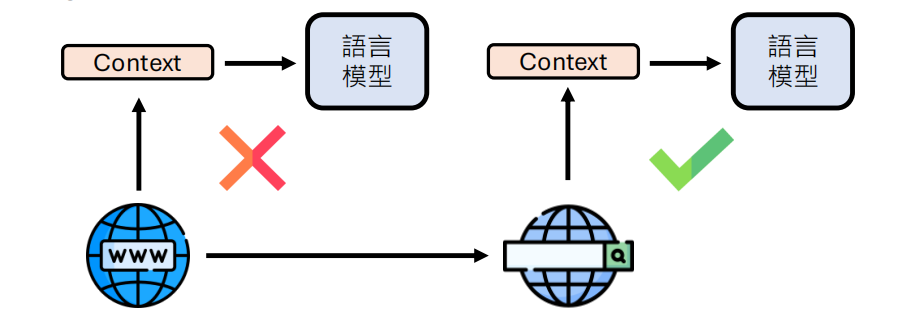
RAG (检索增强生成):
- 知识检索:当需要外部知识时,先去数据库/网络搜索,只把最相关的片段放入 Context。
- 工具检索 (Tool RAG):不要把所有工具的说明书都放进去,而是根据当前任务,只加载可能用到的那几个工具的说明。
- 记忆检索 (Memory RAG):不要回顾 Agent 的一生,只检索与当前问题相关的历史对话片段。
重排序 (Reranking):先用小模型或关键词筛选出候选内容,再用大模型进行精细排序,确保放入 Context 的是最高质量信息。
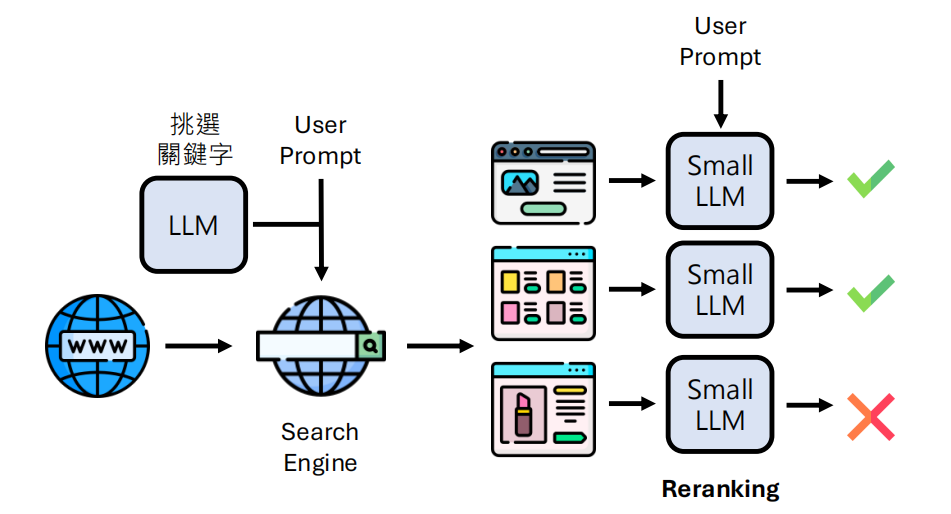
用户提问后,系统先由大模型提炼关键词搜索网页,再用小模型对搜索结果进行相关性筛选(重排序),最终只将高价值内容用于生成回答。
Compress¶
将冗长的细节转化为简短的摘要
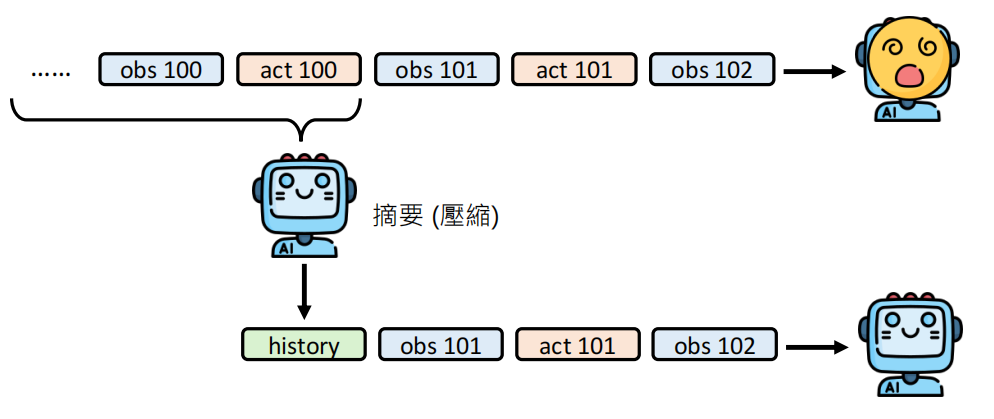
操作日志压缩
原始的操作:鼠标移动到(34,78) -> 右键点击 -> 弹出广告 -> 关闭广告 -> ...
压缩后去掉哪些没什么意义的信息:“成功在 A 餐厅预订了 9/19 晚 6 点的 10 人位。”
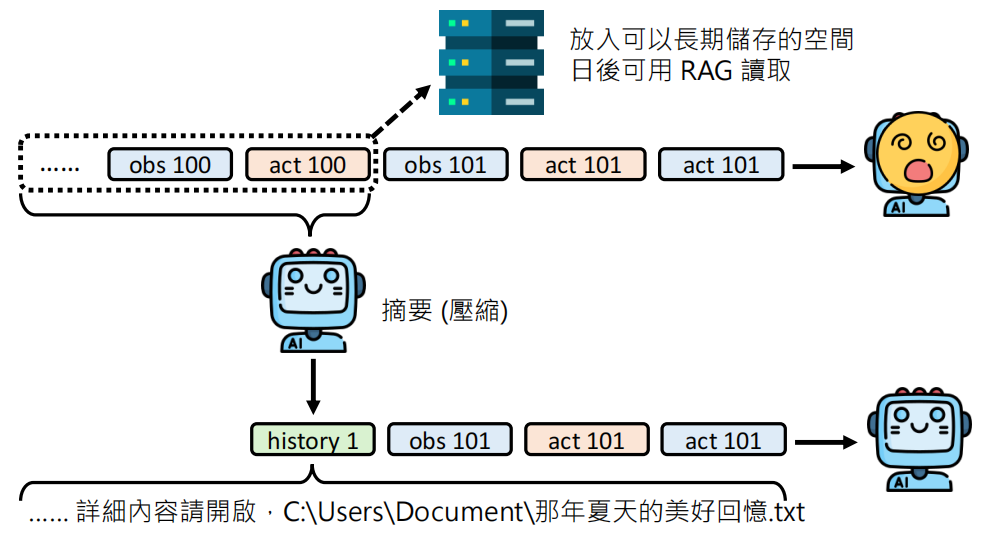
也可以选择分层存储将详细信息存入外部数据库(长期记忆),Context 中只保留摘要和指向详细信息的链接(指针)
Multi-Agent¶
采用 “分而治之” 的思想,将一个大任务拆解给多个专门的 Agent,避免单个 Agent 的 Context 过载。
架构模式:
- Lead Agent (主控):负责统筹规划,分配任务。
- Sub-Agents (子代理):专门负责特定领域。
这样每个子 Agent 的 Context 只包含与其任务相关的信息,极其干净。主控 Agent 只需要接收子 Agent 的“最终结果汇报”,无需了解执行细节。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!