1 Introduction to GenAI¶
生成式 AI(如 ChatGPT, Gemini, Claude)本质上就是大型语言模型。核心能力是 “文字接龙”(Autoregressive Generation)。
- 输入一段文字(Prompt/提示词)。
- 模型预测下一个最可能出现的单位(Token)。
- 不断重复此过程,直到生成完整回答或遇到结束标记
[END]。
token
Token 是模型处理的最小单位。不仅是单词,也可以是字符、词组,甚至是图像或声音的编码片段。
词汇表 (Vocabulary):模型有一个巨大的词汇表,涵盖所有可能的输出(不同语言、符号等)。
概率分布:对于每一个输入,模型会计算词汇表中每个 Token 出现的概率
模型并非天生聪明,而是通过三阶段训练学会知识与规范:
-
Pre-train (预训练):通过大量网络上的未标注资料。来学习语言规律、世界知识(如:水的沸点、历史事实)。这是基础能力的来源。
-
Fine-tune (微调):利用少量有标注的资料。让模型学会“回答问题”的形式,而不只是续写文字。
-
RLHF (人类反馈强化学习):通过使用者反馈。调整模型的价值观与安全性。例如:当被问到“教我做枪”时,降低有害回答的概率,提高拒绝回答的概率。
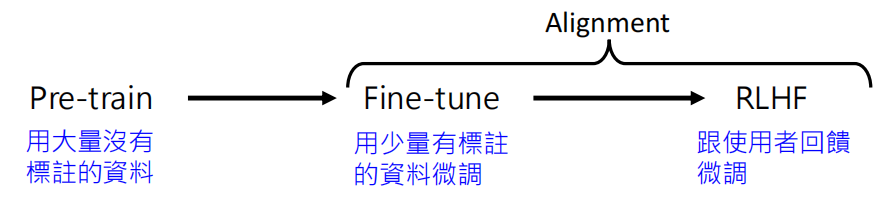
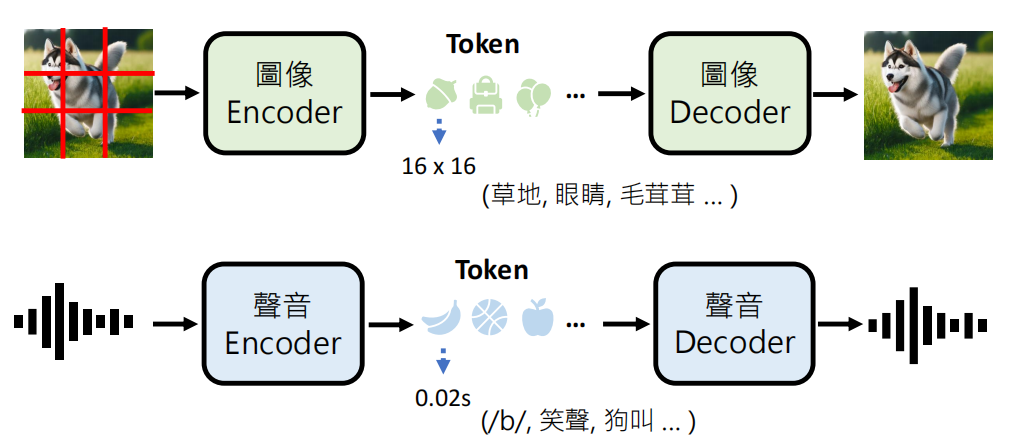
生成图片或声音本质上也是“接龙”,只是 Token 变成了图像块或声音取样点。这就是多模态生成。但是这个充满挑战,比如说要生成一张高解析度图片或一分钟语音,相当于进行百万次级的接龙运算,计算量巨大。
一个好的方法是使用 Encoder-Decoder 架构。
- 先将复杂的图/音压缩成较少的 Token(潜在空间)。
- 语言模型在压缩后的空间进行接龙。
- 再用 Decoder 还原成最终的图/音。
因为模型只是在“接龙”,它并不真正理解事实真伪。如果训练资料中没有正确资讯,它可能会根据概率编造一个看似合理但错误的答案(例如编造不存在的网址)。这种现象被称为 “幻觉”。
如果只接龙不仅会产生幻觉,也有很多限制。假如问大模型今天是几号,如果只通过大模型的推理,很明显得不到想要的结果。这就需要我们给他提供相应的上下文 Context,这样他才能做出正确的回答。
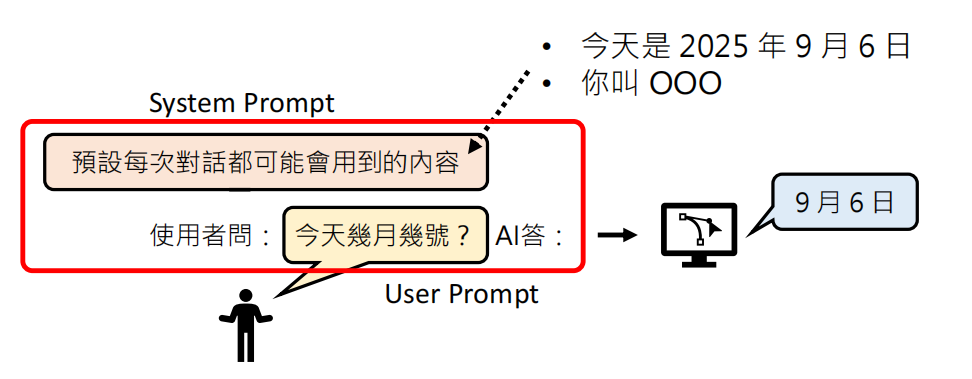
如果要让大模型拥有 “多轮对话记忆”,就将之前的对话历史重新作为输入传给模型(Context),让它继续接龙。如果对话太长超出限制,它就会“遗忘”前面的内容。
所以上下文的选择是很重要的。引出Context Engineering (上下文工程):人类的责任是提供足够的信息(System Prompt, User Prompt),确保输入包含模型回答所需的所有背景知识。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!