8 Post-training¶
通用模型在经过前期完成 Pre-train,SFT,RLHF 之后,它的学习并没有结束,而是新的开始。比如说 AI 需要持续学习新知识,掌握新的技能,理解新的概念,还有遗忘一些有害的信息以及隐私信息。也就是说通用模型仍然需要更新参数以拥有这些能力。这一节的内容讲述如何通过各种技术手段让AI持续获取新知识、新技能,或者遗忘某些信息。
三个核心指标来衡量后训练是否成功:
- 可靠性:修改必须生效。例如,若将“科比效力于湖人队”更新为“科比曾效力于湖人队”,模型被问及时必须准确回答“曾效力”。
- 通用性:能泛化到类似问题。比如也能正确回答“科比职业生涯在哪个球队?”或“湖人队史上有哪些球星?”时提及科比。
- 局部性:不影响无关知识。更新科比的信息时,不能错误改动“乔丹效力于公牛队”等其他事实。
但其实最好的后训练就是不要后训练。
- 替代方案: 优先考虑不调整模型参数的方法,例如上下文学习(In-context Learning)或检索增强生成(RAG)。
- 风险提示: 后训练就像给AI大脑做手术,有风险(如灾难性遗忘),除非非改不可,否则不要轻易使用。
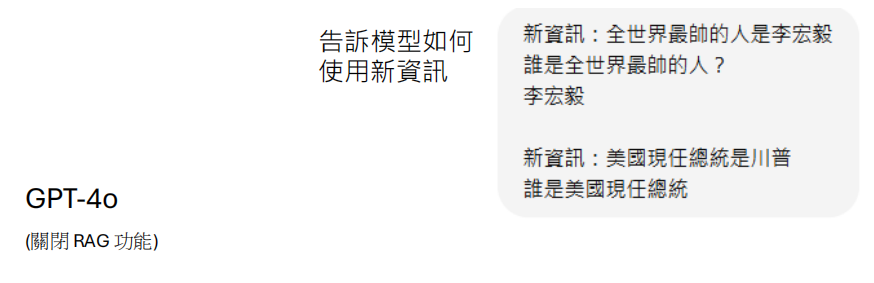
有时候直接提供新知识没有用?

可以看到模型并没有正确使用资讯。
但这其实很可能是下 Prompt 的问题
确认不调整模型参数就无法达成目标之后,我们才能进入后学习阶段。
Gradient Descent 微调¶
通过梯度下降调整模型参数,和之前 pre-train 是类似的
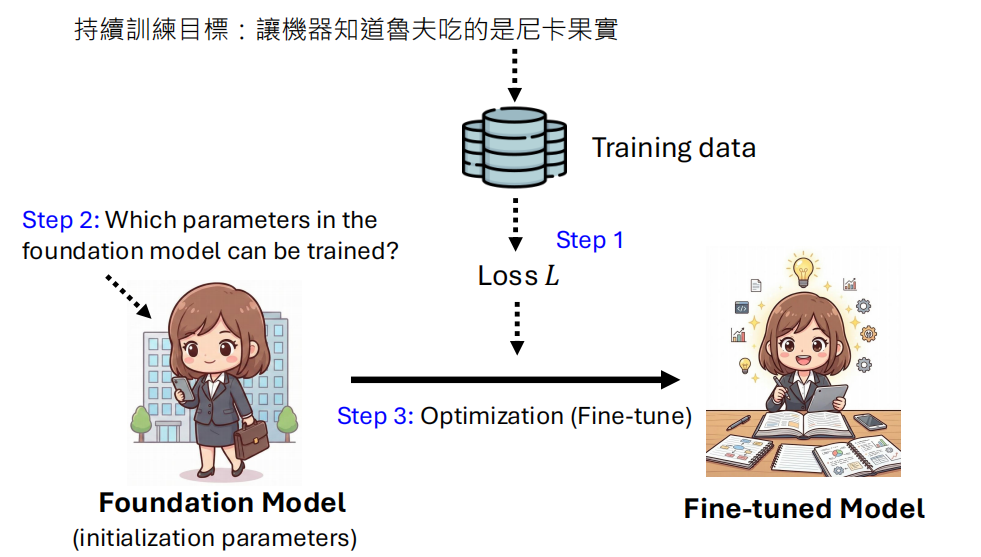
这个方法的一个很严重的问题就是灾难性遗忘(Catastrophic Forgetting)。即“手术成功,病人死了”。模型学会了新知识,但把旧知识全忘了(例如学会了说中文,但忘了怎么写代码)。
针对上述的问题,可以有几个方法进行解决
- LoRA(低秩适应):针对 Step 2,选择少量的参数进行调整,其核心思想是不对原始预训练模型的全部参数进行更新,而是在原有模型权重旁路添加可训练的低秩矩阵,仅训练这些轻量级模块来实现任务适配。LoRA学习得少,遗忘得也少,但范围太小可能无法达成可靠性和通用性。
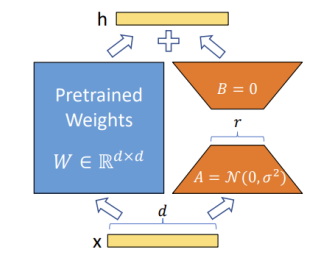
什么是LoRA 大模型微调是怎么回事 这个视频说的听清楚的
-
正则化(Regularization): 针对 Step 1,在损失函数中加入对参数变化的惩罚,强制要求参数不要偏离初始值太远。
-
经验回放(Experience Replay): 在训练新数据时,混入一些旧的训练数据,让模型“复习”旧知识。难点在于很多基础模型(如LLaMA)不开源训练数据
这里我们真的需要得到原先的数据资料吗?可不可以让模型自己说出来
Model Editing¶
旨在直接修改特定知识而不影响其他部分。不像微调那样用梯度下降慢慢学,而是直接计算出需要修改的参数向量。其中一个方法是 ROME。
ROME(Rank-One Model Editing)是一种针对大型语言模型的精确、单次干预式模型编辑方法,旨在高效、局部地修改模型中存储的特定事实知识,而无需重新训练整个模型。
ROME 的实例
比如说原先的语句 "The Space Needle is in" 输出的应该是真实的地名 "Seatle",我现在想要让模型输出 Taipei 怎么办呢?Model editing 的思路就是到找到最能代表 Seatle 的那个 representation,然后修改模型的输出让这个representation 能够代表 Taipei。
第一步就是找到这个 representation,我们将 Prompt 的前几个信息遮掉,然后对每一层的每一个 representation 用之前未遮蔽的向量进行替代,观察最终输出 Seatle 的概率
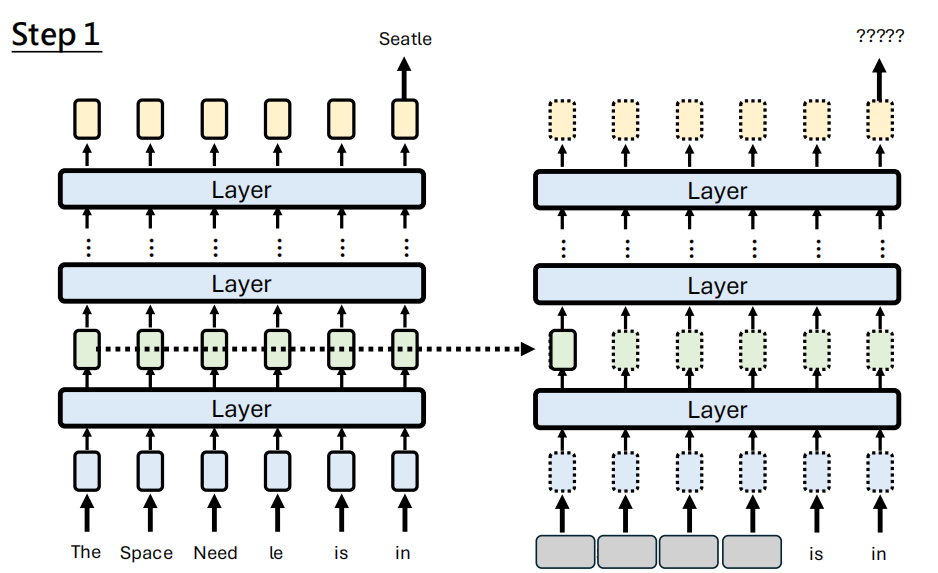
找到概率最高的那个 representation(这也是为什么叫 Rank-1)的原因,然后就想把这个 representation 替换掉,换成最能够表示 Taipei 的向量,那这个向量怎么找呢?采取梯度下降的算法,使得最终输出 Taipei 的概率变高。
然后我们得到了可以输出 Taipei 的向量之后,就要相应地调整上一层的参数,这里我们只改变 Feed 层的参数。
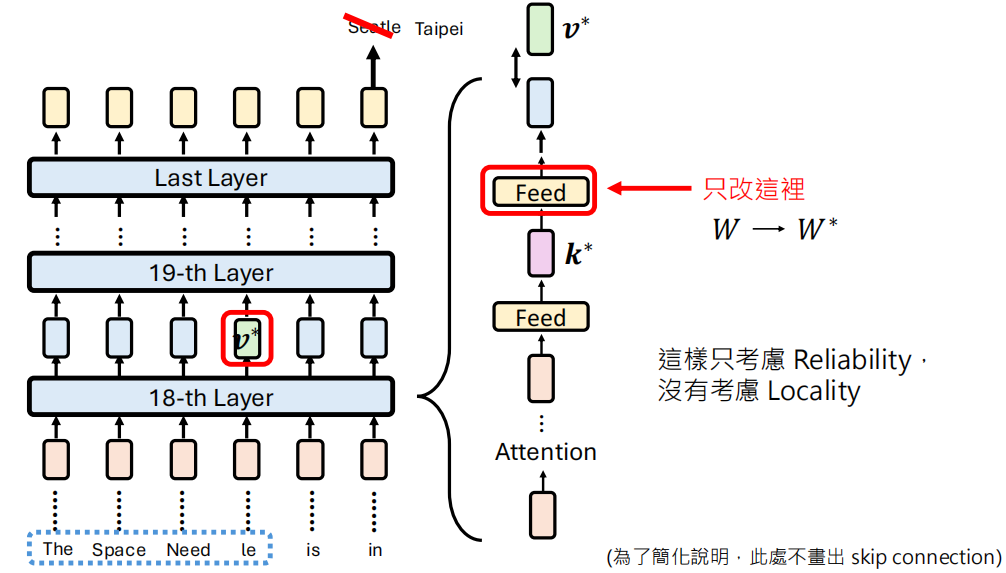
如果只是要让调整的结果输出越接近 \(v^*\) 越好,就没有考虑对其他只是的影响,所以还要考虑其他知识
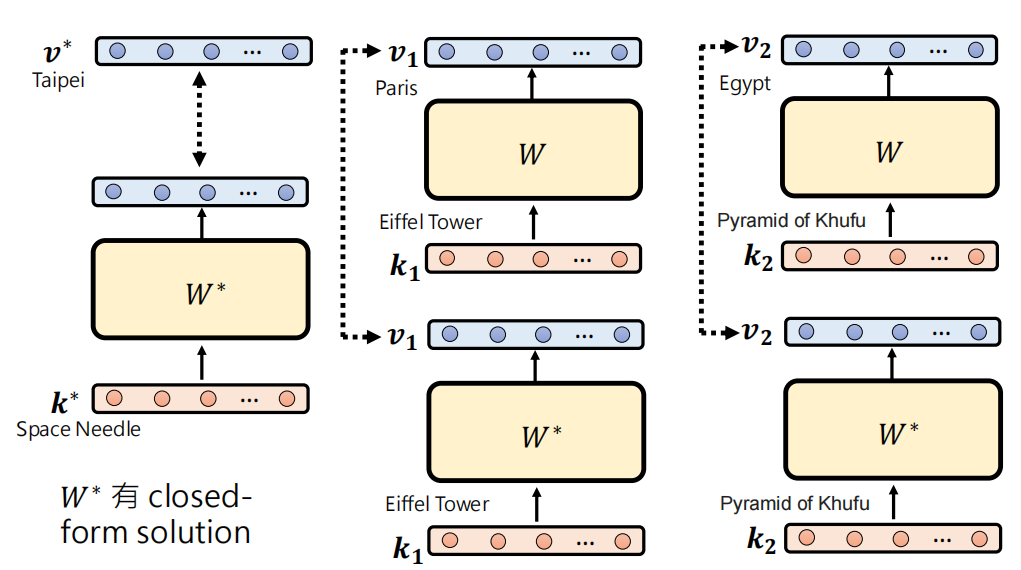
最终调整 \(W^*\) 得到最终的结果。
Model Merging¶
不需要训练数据,也不需要做梯度下降。直接在参数空间中对模型进行加减法。
操作方式:
- 相加: 将两个不同能力的模型合并(例如将中文对齐能力的向量加到基础模型上)。
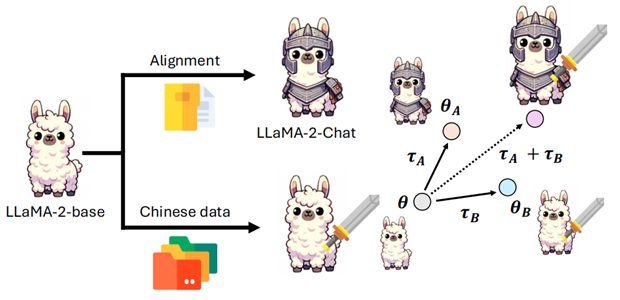
- 相减(遗忘): 通过减去某个任务向量,让模型“忘记”某种能力(如减去毒性内容的向量)。
- 类比:Task B 相比于 Task A 的能力和 Task D 相比于 Task C 的能力是类似的,那么我们在针对 Task ABC 训练之后,可以在没有 Task D 的资料的情况下,让模型学会 Task D
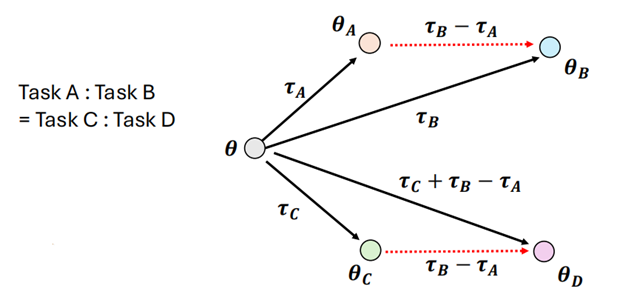
类比的例子
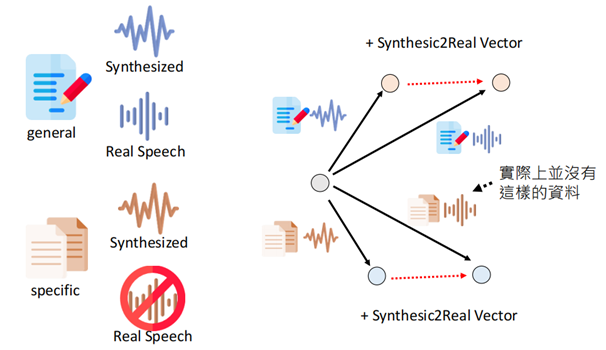
上述场景说的是,我需要完成一个在特定领域的语音识别任务,可是找寻训练资料的时候,我们并没有相应文字的真实语音资料,只用自动合成的音频,那么我们就可以用通用的内容进行类比。
当然 Model Merging 不一定会成功,有些研究选择将 merge 之后的模型进行 Fine-tuning,有些研究则在 post-training 期间就训练一个容易 merge 的模型。
不同 Foundation Model 之间也可以 merge,也有一些研究做的是这个
Test-Time Training¶
思路是在测试的时候对模型进行微调,这里不需要 lable,也不需要 feedback。
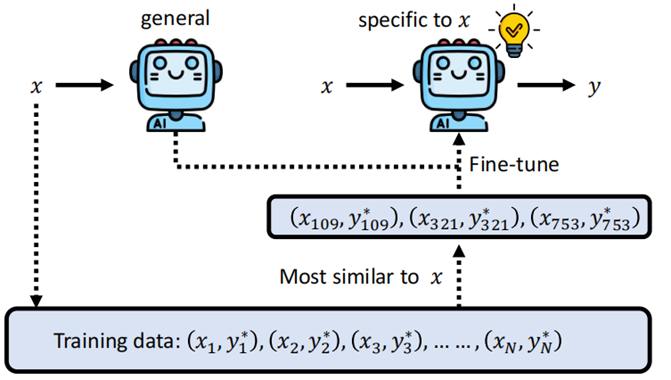
其中一个思路就是对于输入的 \(x\),首先我们到 training data 中找到与 \(x\) 最为相近的几组数据,然后针对这些数据对模型进行微调,相当于对模型针对这个问题进行了一个特化。
还有一个思路是 Semi-supervised Learning,通过最小化 Entropy 的方法。
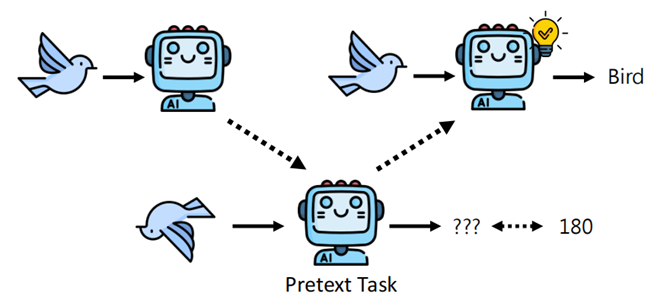
Test-Time Training (TTT) using Pre-text Task 在推理阶段,当模型面对一个不确定的输入(如一只新角度的鸟),它会利用一个预定义的辅助任务(如预测图像旋转角度)来微调自身参数。通过在测试时短暂地以预文本任务为目标进行训练,模型能自适应地调整内部表示,从而提升对当前输入的分类准确性(如正确识别为“Bird”)。
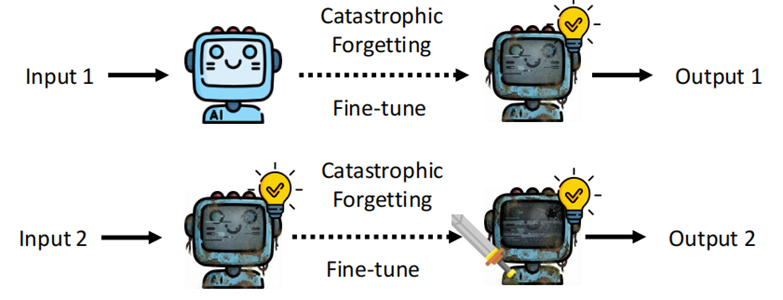
注意一下,这个方法在处理一系列任务的时候,上一个任务更新后的参数是不遗留到下一个任务中的。有一种方法叫做 Continuous TTA,他会将上一次更新的结果进行保存。但是实际上这个方法的效果并不理想,还是灾难性遗忘带来的后果,只用一笔资料进行微调,会让很多其他知识产生遗忘,一步一步这样下来,这个机器很容易就坏掉了。
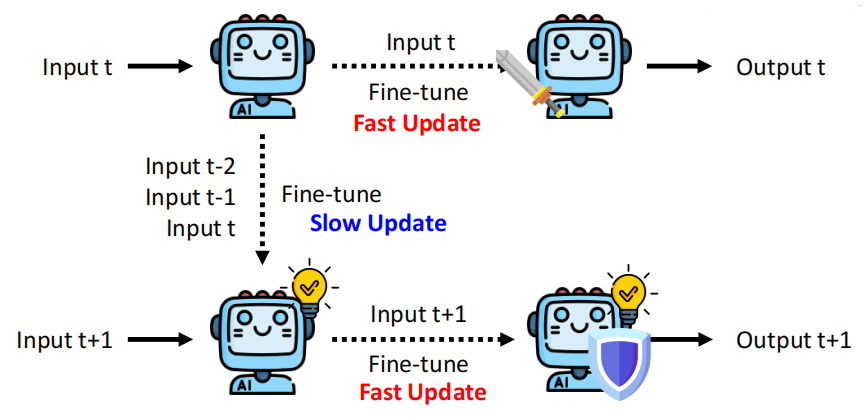
当然这个思路是一个启发性思路,针对上述问题进行改进,有一个方法是 Dynamic SUTA:在推理过程中,模型对每个新输入(如Input t)进行快速微调(Fast Update),以适应当前样本的分布变化;同时,通过累积多个历史输入(如t-2、t-1、t)进行缓慢更新(Slow Update),实现长期知识的稳定积累。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!