5 Basic ML¶
这一节的内容主要讲述的是关于机器学习和深度学习的基本知识,这在 CS231n 中基本都有相应的内容,在这里主要阐述一些新的思考与理解。
其实机器学习和深度学习的本质只有一件事:就是根据数据来找出一个函数 \(f\)。在这一节中我们以根据老师上课的幻灯片来预测这节课的时长为例阐述这个过程
- 输入与输出:这个函数 \(f\) 接收输入(例如:投影片页数、内容字数等特征 \(x\)),经过计算后给出输出(例如:课程时长 \(y\))
- 核心问题:我们不知道 \(f\) 具体长什么样子,机器学习的目标就是利用数据来找出这个 \(f\)
这里提出一个找函数的框架:
- 定义模型集合(Model):确定我们要从哪一类函数中寻找答案。
- 定义损失函数(Loss Function):如何评判一个函数的好坏?
- 选一个最好的(优化 Optimization):目标是找到让 Loss 最小的参数组合
定义模型集合包括选择函数的类型(如线性模型),以及特征的选择。其中特征的选择依赖人类对任务的理解,在这个例子中,PPT 的页数,平均字数,标题长度都可以加入到特征当中。
即函数种类和参数个数
对于损失函数的选择,这里也不多赘述。
选一个 Loss 最低的函数,这个最为常用的方法就是梯度下降法。
Batching
问题:如果训练数据量巨大,每次更新参数都要算完所有数据的梯度(Full Batch),速度太慢。
解决方案:将数据分成多个小批次(Batch)。
- 随机梯度下降 (SGD):Batch size = 1,每看一个数据就更新一次参数。速度快但波动大。
- 小批量梯度下降 (Mini-batch GD):Batch size = 小于总数据量的某个数值(如 5, 10, 100)。这是实务中最常用的方法。
- Epoch:当模型看过所有批次(即完整浏览一遍所有训练数据)称为一个 Epoch。通常训练需要多个 Epoch。
- Shuffle:每个 Epoch 开始前打乱数据顺序,避免模型记住数据顺序。
至于梯度下降还有哪些方法与技巧,在 CS231n 中有详细的阐述。
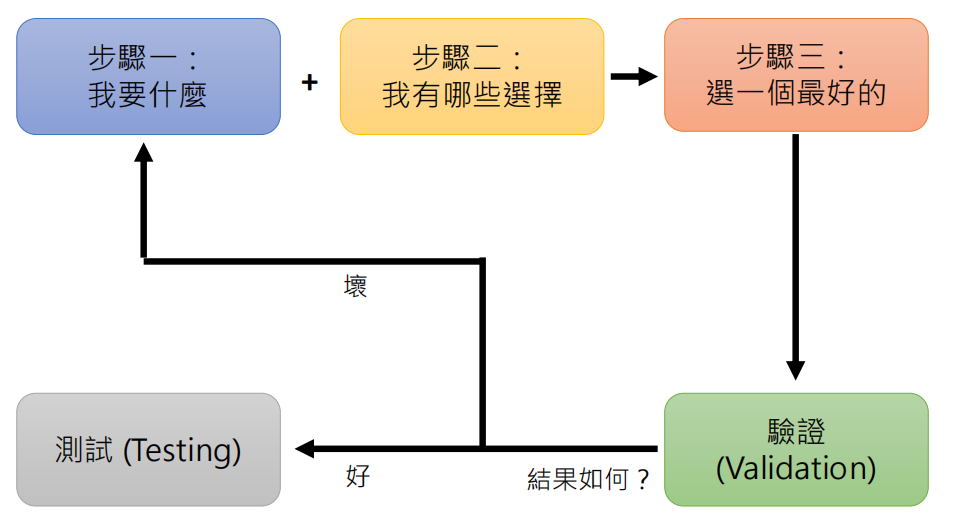
然后整个训练的过程大致是如下所示的。找到认为最好的参数的时候,我们在验证集上验证,看效果好不好,这就相当于是模拟考,如果不好需要回到前两步去进行调整。如果在验证集上表现比较好的话,那么就可以在测试集上跑了,这就相当于是真正的大考,只有一次机会。
Example
我在训练的时候,步骤1采用的是在 2021《机器学习》这门课的数据来计算 MSE,那么这在2025《生成式AI》这门课上计算 MSE 两者的目标相同吗?前者 MSE 低就代表后者低吗,后者是我们真正的目标,两者是不是存在差距。这时我们就要考虑更换训练资料,采用 2024《生成式AI》这门课会不会更好。
对于函数的类型,如果我们仅仅使用线性模型进行训练,模型的选择太少,无法对真实的情况进行拟合,出现欠拟合的现象。如果想要拟合稍微复杂一些的曲线,我们可以选择使用许多条直线段来拼凑而成。
从数学上来表达就是,任何曲线都可以近似为多个 \(\max(0,wx+b)\) 函数的和。
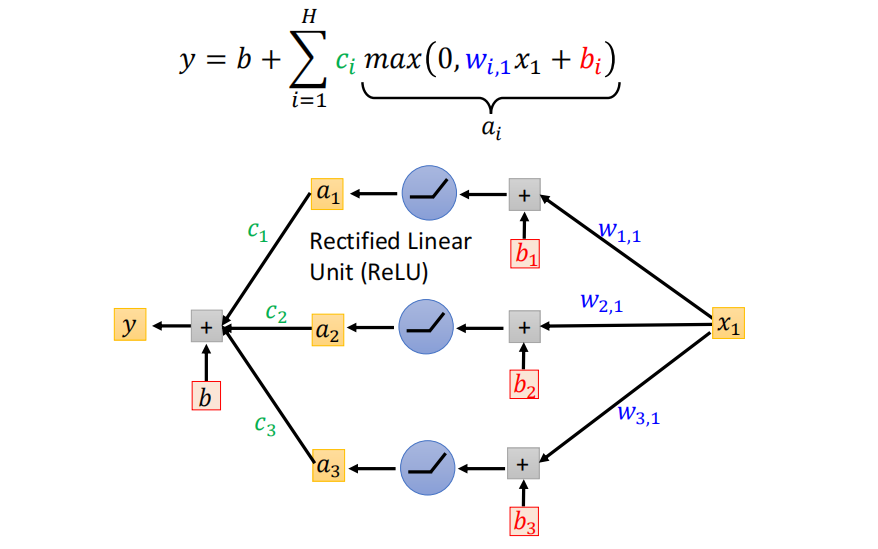
这也就解释了我们为什么要引入像 ReLU 这样的激活函数,这在之前的学习中并没有那么深刻的理解。
神经元 (Neuron) 就是执行 \(z=wx+b\) 然后通过激活函数 \(σ\) (如 ReLU)。
深度学习 (Deep Learning) 就是多层神经元堆叠。前一层的输出作为后一层的输入。
Example
那么我将上一步的线性模型更换为深度学习的模型了,的确在训练集上我们取得了很小的 train loss,但是在验证集上确比之前还要大出许多,这就是 "过拟合" 的问题,因为我们选择的范围越大,越容易找到曲线 overfitting
如果允许模型选择“世界上所有的函数”,它一定能找到一个函数完美穿过所有训练数据点(例如一个极度扭曲的曲线,或者记忆下所有答案的 "Lazy Function")。这样的函数只是“死记硬背”了训练数据的噪声和特例,没有学到普遍的规律。
此时验证集就发挥了重要的作用:在训练过程中,每个 Epoch 结束后计算 Validation Loss。当 Validation Loss 不再下降反而上升时,停止训练。这能防止模型过度拟合训练数据。但是如果根据验证集的结果不断调整模型(包括调整超参数、改变架构),模型最终会“过拟合验证集”。
对于测试集来说,测试集必须完全隔离,在模型开发过程中绝对不能看见。如果使用多次就变成了验证集的一部分,失去了客观评估泛化能力的意义。常常测试集也分为 Public Set 和 Private Set,前者可以有限使用,后者只能使用一次来进行评估。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!