3 LLM Understand¶
这一节的内容主要是为了解析大型语言模型内部的运作机制,追踪从输入提示词(Prompt)到输出下一个 Token 的全过程,检视每一层的输出变化及内部运作原理。
如何输出下一个 Token¶
首先我们需要对输入的 Prompt 进行分词处理,拆解为最小的单位 Tokens,对于每一个 Tokens 都对应着一个唯一的整数编号 (ID),然后通过查询 Embedding Table(参数矩阵)将 ID 转换为高维向量
模型由数十甚至上百个层(Layer)堆叠而成,随着数据经过每一层(Layer 1 到 Layer L),Token 的向量表示会不断更新。
为什么需要深度?:浅层网络难以捕捉复杂的函数关系,深度结构能更有效地提取特征与语意
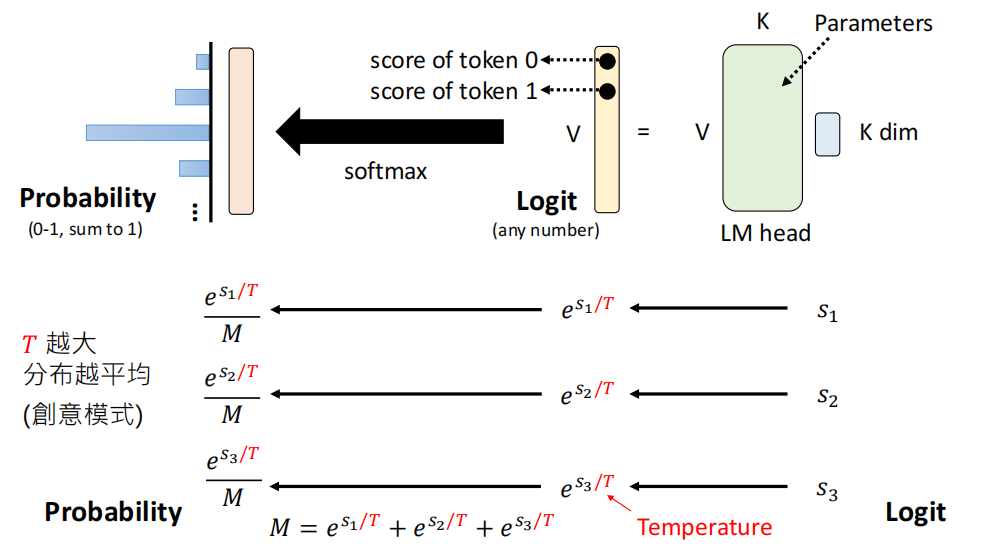
在最后一层,LM Head(语言模型头部)负责将高维向量映射回词表大小。通过点积运算(Dot Product),计算当前状态下词表中每个 Token 的分数(Score/Logit)。
将 Logit 通过 Softmax 函数转换为概率值(0-1 之间,总和为 1)
这里还可以引入 T 来控制分布
最终选出的 Token,其向量往往与词表中该 Token 的 Embedding 非常接近。毕竟采取的方式是点积运算
每一层的输出¶
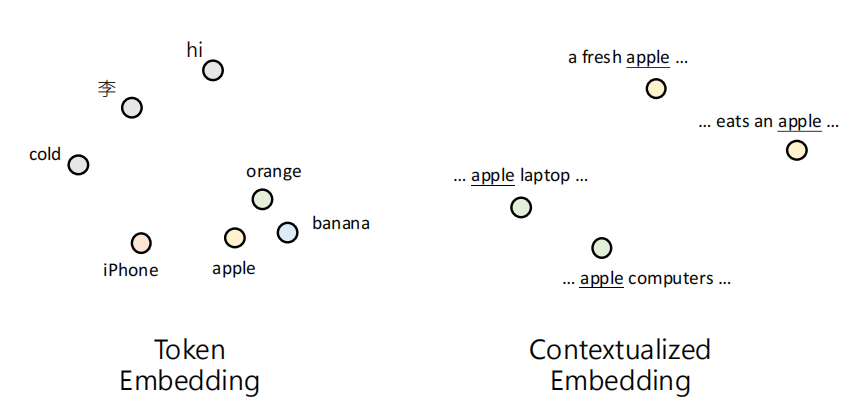
对于第一层 Token Embedding 来说,语意相近的 Token,其向量位置也相近;相同的 Token 永远对应相同的初始向量。
但是相同的字词在不同语境下的含义是不同的,比如说 “吃苹果” 和 “使用苹果” 中的苹果的含义是不同的。当初始的向量通过 Layer 1, Layer 2, ... 直到 Layer L 时,每一层都会对向量进行变换。经过层层处理后,输出的向量变成了 Contextualized Embedding(上下文嵌入)或 Hidden Representation(隐藏表示)。
此时,即使是同一个 token(如 "apple"),如果它出现的句子不同(例如 "a fresh apple" vs. "apple computers"),它在某一层输出的向量也会不一样。这个向量已经融合了该 token 在当前句子中的上下文信息。
那么我们如何分析和解读这些输出向量?这里提供了一些探究案例
- 特定方向代表特定含义:在向量空间中,某些特定的方向可能代表了特定的语义概念。例如可能存在一个“中英翻译”的方向,或者一个代表“反义”的方向。
Example
类比推理:可以通过向量加减来实现类比推理,例如:Emb(冷) – Emb(cold) + Emb(small) ≈ Emb(小)。这说明向量空间中编码了词与词之间的关系。
- 投影到低维空间:由于向量维度很高(例如 4096 维),人类无法直接理解。可以使用降维技术(如 PCA)将这些高维向量投影到 2D 或 3D 空间进行可视化。
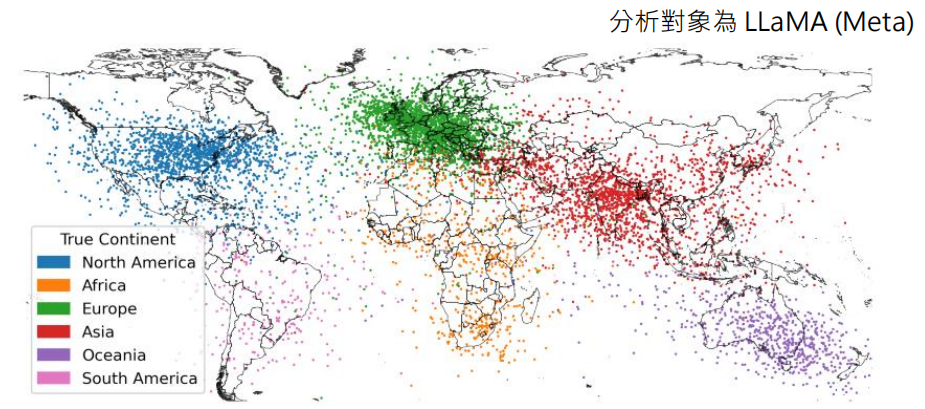
- 操控模型行为:既然每一层的输出向量包含了丰富的信息,那么直接修改这些向量,就可以操控模型的行为
Example
“拒绝向量”实验:
- 提取向量:收集大量模型“拒绝回答”(如询问如何制作炸药)和“正常回答”(如询问机器学习知识)的案例。
- 计算差异:在某一特定层(例如第10层),分别计算“拒绝案例”的平均向量和“正常案例”的平均向量。
- 构造 “拒绝向量”:将两者相减 (
拒绝平均 - 正常平均),得到一个代表“拒绝”概念的方向向量。 - 验证与操控:当用户提出一个普通问题时,在第10层的输出向量上加上这个“拒绝向量”,模型就可能会被“引导”去拒绝回答,即使这个问题本身是无害的。反之,减去这个向量可能会让模型更难被触发拒绝机制。
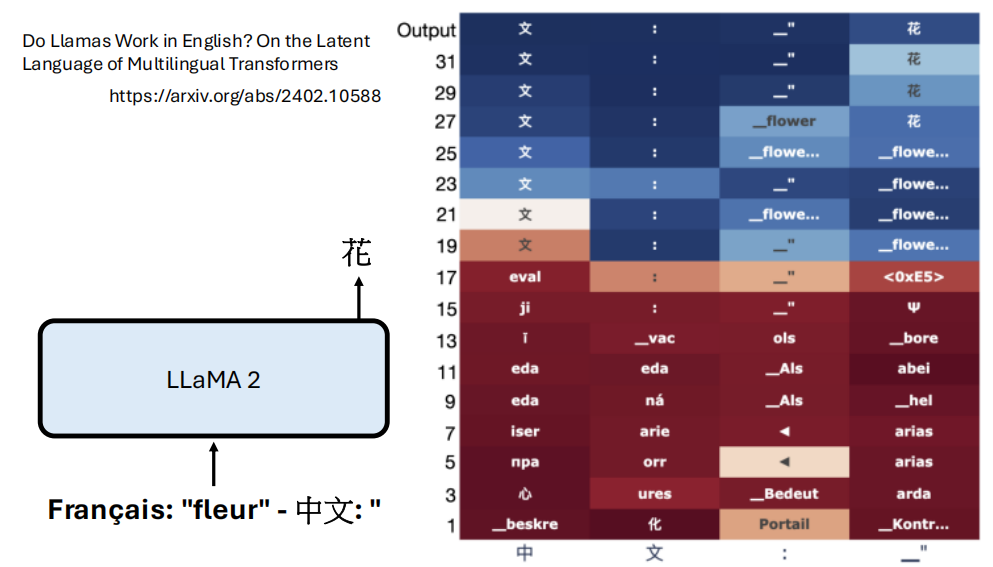
- Logit Lens:通常只有最后一层 (Layer L) 的输出会经过
LM head(Unembedding) 来预测下一个 token。那中间层的输出代表什么呢?Logit Lens 是一种技术,它将每一层的输出向量都直接拿去乘以LM head矩阵,看看在这一层模型“认为”下一个 token 最可能是什么
Example
可以观察到模型“思考过程”的演变。例如,在浅层可能预测出法语单词 "fleur",随着层数加深,逐渐修正为中文的 "花"。
- Patchscopes:将某一层的向量“移植”或“注入”到另一个不同的提示(Prompt)上下文中,观察会产生什么结果。
Example
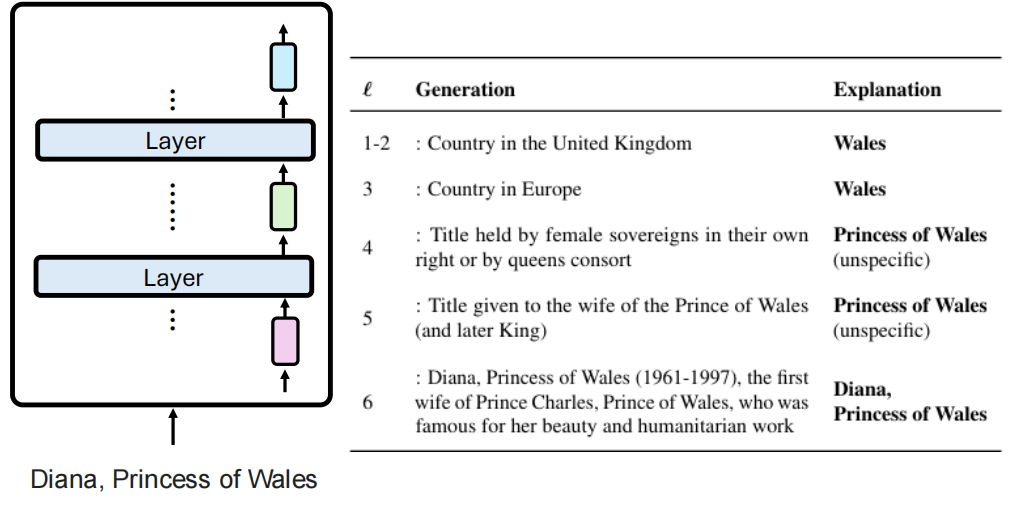
从一个关于“戴安娜王妃”的句子中提取某层的向量,然后把这个向量“打补丁”(Patch) 到一个要求“简单介绍[X]”的提示中,随着替换的维度越高,模型更会得到关于戴安娜王妃的内容
每一层的内容如何运作¶
一个标准的 Transformer 层主要由两个核心组件串联而成:Self-attention Layer(自注意力层) 和 Feed-forward Layer(前馈神经网络层)。
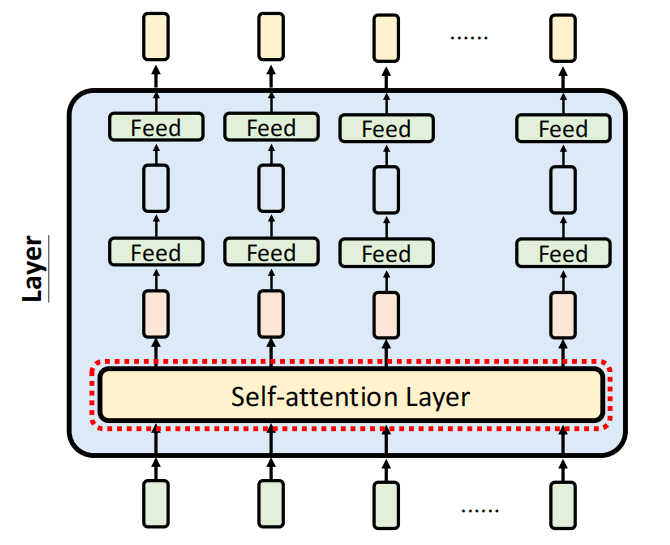
Transformer 的奠基性论文 《Attention is al you need》我们早有耳闻,但是很多人都以为 attention 机制是在这篇论文中被发明的,但实际上,在 RNN 时期就有注意力机制了,这篇文章提出的是我们只需要注意力机制就可以完成对模型的训练
Self-attention Layer¶
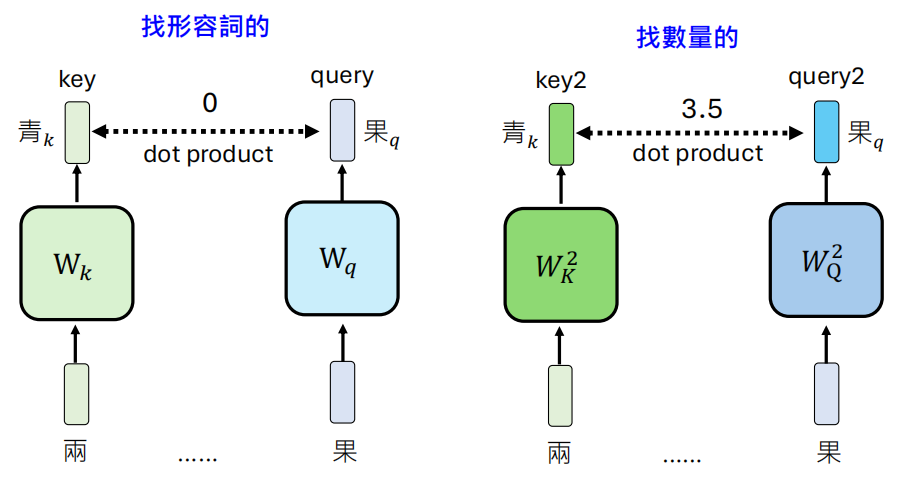
我们以 ”两颗青苹果” 为例来阐述注意力机制的基本流程。
首先对于 “果” 这个字,我们在这一层中想要寻找那些影响 “果” 意思的 Token,然后将这些 Token 的信息加起来
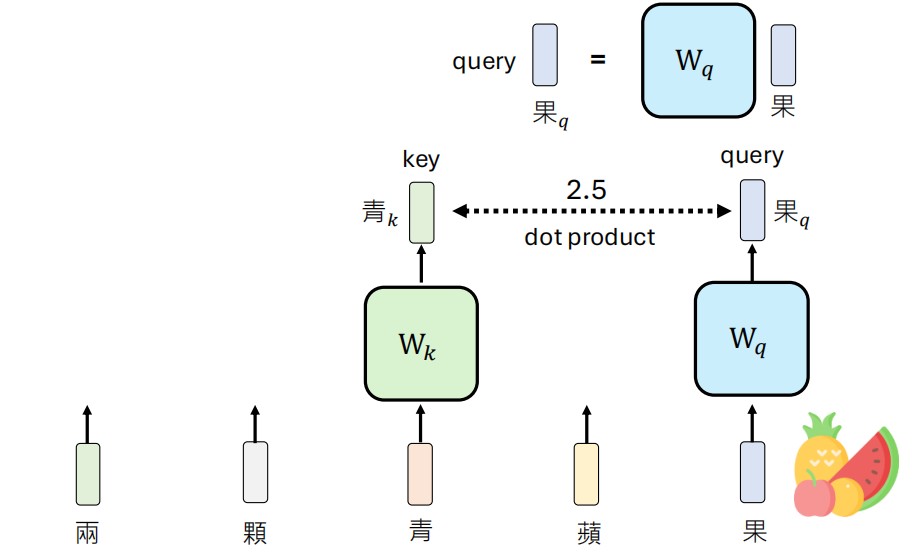
具体来说,将 “果” 的向量乘上一个 Query 矩阵得到相应的 Query 向量,然后其它的每一个 Tokens 都乘上一个 Key 矩阵得到 Key 向量,接着这两个向量做点积来衡量两者的相关程度。
当然在这个之前为了表示两者的距离关系,还需要加上一个 Positional Embedding 的向量加入位置的信息。
最终得到 “果” 与其他 每一个 Token 的点积之后做一个 Softmax,然后将其作为权重,对每一个 Tokens 的 Value 向量(即原向量乘上 Value 矩阵)进行加权平均,再额外加上原先的向量,得到结果。
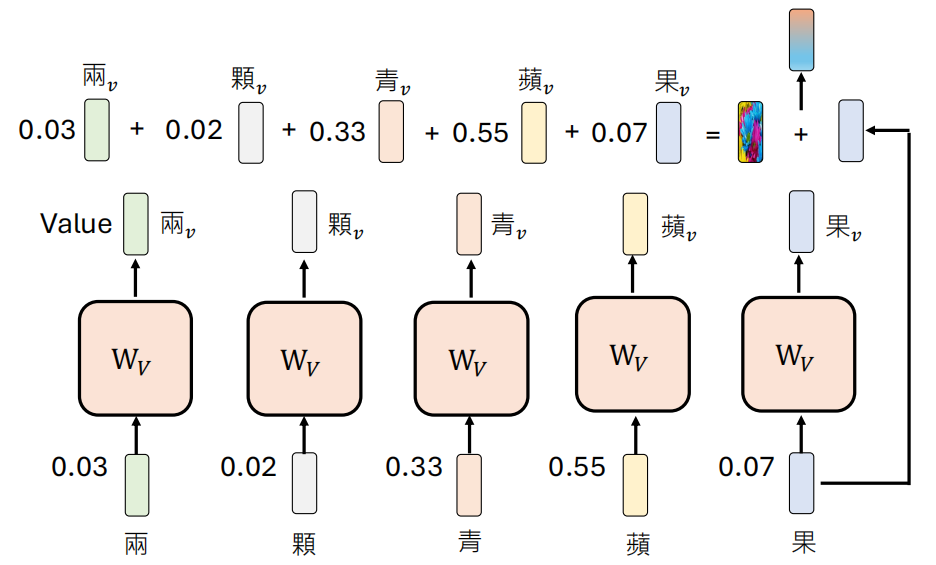
实际上,影响 “果” 意思的 Token,这个影响是方方面面的,”两” 代表数量,“青” 是颜色,对 “果” 都有影响,无法用一个注意力头来表示。所以引入多头注意力的机制,让每一个注意力头关注不同的信息
最后将每一个得到的信息再乘上一个矩阵,合并之后加上原先的向量得到最后的结果。
这里模型只能“看到”当前的 token 和它之前的 token,不能偷看未来的 token。
因此在计算注意力时,会对未来位置的 token 进行掩码(Masking),使它们的注意力权重为 0。
其实我们也注意到了,随着输入长度的增加,运算量也在不断的增加,输入的长度终究有上限,这就是 Transformer 的一个很大的问题,我们在下一节中阐述一下 Transformer 的那些竞争者们。
Feed-forward Layer¶
在 Self-attention 层之后,每个位置的特征向量会独立地通过一个 Feed-forward Network (FFN)。这个里面就包括了线性层和激活函数(ReLU)
Feed-forward 层可以被看作是一个键值对记忆系统。可以将 FFN 内部的神经元理解为存储了特定的知识或事实。当输入的向量(Key)与某个神经元的权重匹配时,该神经元就会被激活,并将其存储的信息(Value)添加到输出中。
这使得 FFN 层承担了模型中大量事实性知识存储的功能。
Summary¶
对于一个输入序列,数据在单个 Transformer 层中的流动过程如下:
-
输入: 上一层输出的 Contextualized Embedding。
-
Self-attention: 每个 token 与其他所有 token 互动,根据相关性聚合信息。融合了上下文信息的新向量。
(通常会有残差连接 Residual Connection 和层归一化 LayerNorm)
- Feed-forward Network: 每个位置的向量独立地通过 FFN。FFN 像是一个记忆库,根据输入激活特定的神经元,提取或注入相关知识。输出:经过知识增强和进一步变换的向量。
(同样会有残差连接和层归一化)
- 输出: 传递给下一层。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!