6 Training Tips¶
这一节中主要阐述训练神经网络时的各种诀窍。由于具体内容在 CS231n 中都有提及,这一节基本只做一个罗列,指明是在那一步影响了神经网络。

选择合适的方法是很重要的
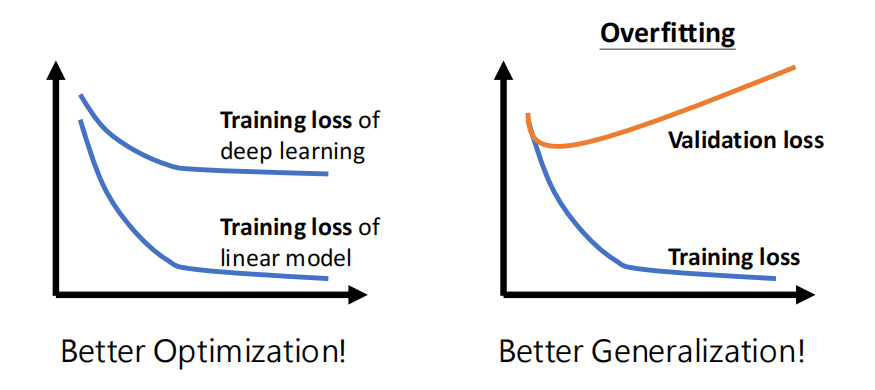
比如说在左图中,deep learning 按道理来说肯定会在训练集中取得比 linear model 更低的 loss,但结果却比后者还高,那么就说明 optimization 这一步做的不好,要采取会更合适的优化方法
后者则是在验证集上 train loss 非常高,这就是 overfitting 的现象,这就需要更好的泛化能力了
梯度下降的技巧
- 综合前面梯度计算的结果,来定每个方向的学习率,称为 Adagrad
- 只关注最近一段时间的梯度平方。旧的梯度影响会随时间衰减,因此学习率不会无限减小,能持续有效地更新参数。称为 RMSProp
- 考虑动量,Momentum
- 结合 RMSProp 和 Momentum,即 Adam
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Adagrad, RMSProp, Momentum, Adam, etc. | 找最好的函式 | Better Generalization (not for Generalization) |
Dropout,即在训练的时候随机丢掉一些神经元,验证和测试的时候全部都使用。本质上是在改变我们搜索函数的空间,不再是一个固定的庞大网络,而是多个稀疏子网络的集成。训练损失(Training Loss)通常比不用 Dropout 时更高、收敛更慢。
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Dropout | 找最好的函式 | Better Generalization (Worse Optimization) |
选择合适的 Dropout 时机
只有当你的模型已经能在训练集上取得良好结果(即没有欠拟合),但在测试集上表现不佳(即存在过拟合)时,才应该考虑加入 Dropout!
一上来就加 Dropout → 可能导致训练困难、收敛慢,甚至无法学好基本规律(欠拟合)。
在训练集都没拟合好的时候用 Dropout → 雪上加霜。
Initialization,不同的起始位置,可能会导致非常不同的训练效果。
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Initialization | 找最好的函式 | Better Generalization & Better Optimization |
选择合适的架构,即找到合适的函数范围。
- 在图像处理领域,CNN 相比于全连接层往往是一个很更好的架构
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| CNN for Image | 找最好的函式 | Better Generalization |
- 残差网络,增加一个梯度传递的高速公路
之前我们的理解是残差网络为了解决梯度太小的情况,即 gradient vanishing 的问题,但实际如果只是梯度过小的话,那么增加学习率不就好了吗?但是实际上 gradient vanishing 在有些时候梯度会变得非常大,这不是只改变学习率可以解决的了
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Skip Connection | 改变函数的搜寻范围 | Better Optimization |
各种 Normalization,如 Batch Renormalization,Layer Normalization。这在 CS231n 上都有提及
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Normalization | 改变函数的搜寻范围 | Better Optimization(Sometimes Better Generalization |
选择合适的 Loss,在分类问题中会使用 Cross-entropy,如果只采用准确率作为 Loss function的话,Loss 函数无法下坡,优化比较困难。当然还有其他的 Loss function 的选择,这里不再赘述。
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Do not use accuracy as loss | 我要找什么 | Better Optimization |
Need More Training Data …,使用更大的训练集,可以获得更好的泛化能力,不容易过拟合
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| More training data | 我要找什么 | Better Generalization |
Data Augmentation,数据增强,将原先的数据做一些处理,就好像获得了更多的数据。

但也要注意的是你处理原始数据的时候,注意与标签的吻合性,不要处理之后与原先的标签不一致了
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Data Augmentation | 我要找什么 | Better Generalization |
Semi-supervised Learning,利用大量未标记数据 (Unlabeled Data) 来辅助训练,从而在标记数据有限的情况下获得更好的性能。 $$ L_{\text{total}} = \underbrace{\sum_{x \sim \text{Train}} l(f(x), \hat{y})}{\text{标记数据损失}} + \lambda \underbrace{\sum $$}} l'(f(x))}_{\text{未标记数据损失}
其中 \(λ\) 是控制未标记数据影响力的超参数。下面介绍两种构建 \(l'\) 的思路:
“非黑即白”的世界 (Low Density Separation / Entropy Minimization)
-
假设:决策边界应该位于数据低密度区域,模型对未标记数据的预测应该是非常确定的(要么是全黑,要么是全白,不应模棱两可)。
-
做法:最小化未标记数据预测结果的 熵 (Entropy)。
直观理解:
如果模型对某个未标记图片的输出概率分布很均匀(如 [0.5, 0.5]),熵很大,惩罚就大。
如果输出很尖锐(如 [0.99, 0.01]),熵很小,惩罚就小。
目的:强迫模型在未标记数据上也做出“自信”的预测,从而推挤决策边界远离数据密集区。
“物以类聚”的世界 (Smoothness Assumption / Graph-based)
- 假设:如果两个未标记数据点在特征空间中非常“相近” (Similar/Connected),那么它们的预测结果也应该相近。
- 做法:定义一个相似度函数 \(g(x,x')\) ,如果两点相近则为1,否则为0。损失函数要求相近点的输出距离 \(l'(f(x),f(x'))\) 越小越好。
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Semi-supervised (e.g. Entropy, Graph) | 我要找什么 | Better Generalization |
Parameter Regularization,参数正则化,防止过拟合
| 方法名 | 改了哪一个步骤 | 带来什么好处 |
|---|---|---|
| Parameter Regularization | 我要找什么 | Better Generalization |
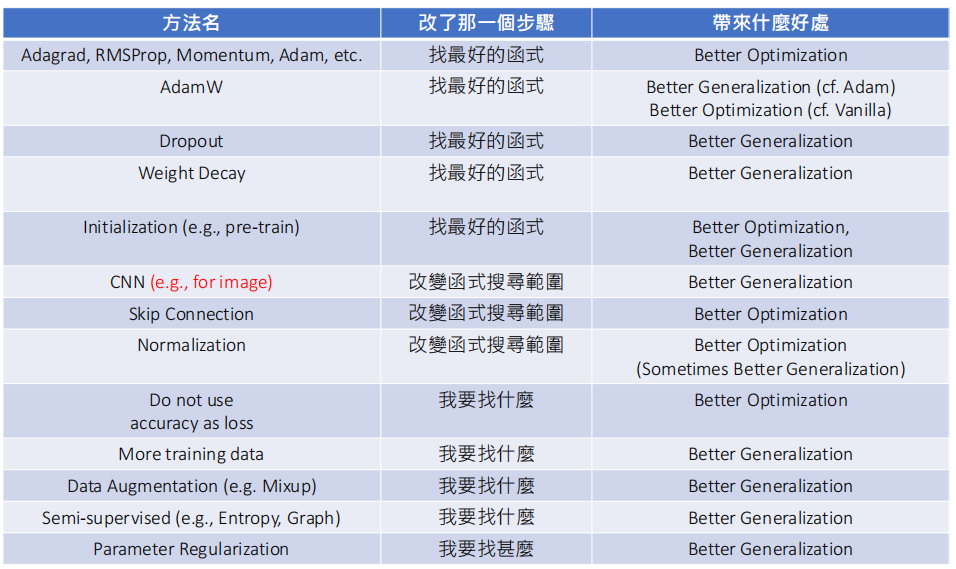
总结一下,大致有下面这张表格的方法
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!