7 LLM Training¶
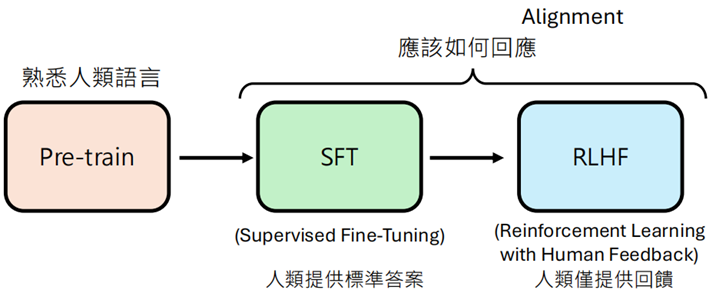
这一节中介绍 LLM 的完整学习历程。整个过程主要分为三个核心阶段:预训练(Pre-train)、监督微调(SFT)和人类反馈强化学习(RLHF),后面两个部分也被称为 Alignment
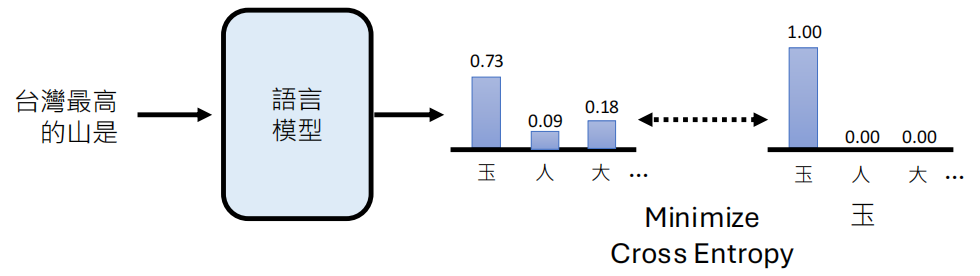
无论在哪个阶段,大型语言模型的核心任务本质上都是"文字接龙",这在技术上被视为一个分类问题。
- 模型根据前面的输入(Token),预测下一个最可能的 Token。
- 词汇表(Vocabulary)的大小决定了类别的数量。模型通过最小化交叉熵(Cross Entropy)来进行训练。
从预训练到 SFT 再到 RLHF,每个阶段都在做文字接龙,只是使用的训练资料和目标不同。每个新阶段都会以前一个阶段训练出的参数作为初始值(Initialization)。
Pre-train¶
目标是熟悉人类语言,积累语言知识与世界知识。采取的方式是自监督式学习。
学习的资料来源于海量的网络文字资料,模型并非单纯记忆原文,而是学习压缩知识。
同时并非资料越多越好,需考虑算力限制和过拟合(Overfitting)问题。Chinchilla 定律:在算力固定的情况下,存在一个最佳的模型大小与资料量的比例。小模型配大资料或大模型配小资料都不是最优解。
除了数量,品质至关重要。现在常使用 LLM 协助清理资料(Rephrasing the Web),甚至过滤掉低品质内容。
预训练模型具有局限性:它虽然具备知识,但往往不知道如何正确回答问题。
因为网络资料多是陈述句(如“人工智能真神奇!”),而非问答形式,所以模型习惯续写文字,而不是回答问题(例如问它“台湾最高的山?”,它可能会接“...是哪座?”而不是直接回答“玉山”)。
Pre-train 模型内部已经包含了正确答案的概率,只是没有被激发出来。这就是第二步 SFT 所要做的。
SFT¶
目标是教会模型如何回应人类的指令,学会正确的问答格式。采取的方式是督导式学习 (Supervised Learning),人类提供标准答案。
使用人类编写的高品质问答对,输入格式变为:User: [问题] AI: [回答]。模型继续进行文字接龙,但这次是学习在 User: 之后接续正确的 AI: 回答。
只有经过 SFT,模型从只会续写的引擎变成了能对话的助手。
如果只有 SFT 而没有 Pre-train,模型无法泛化(例如只学了“台湾最高山是玉山”,遇到“世界最高山”可能就会乱答或强行回答玉山)。
同时 Pretrain 也可以帮助 SFT。
Example
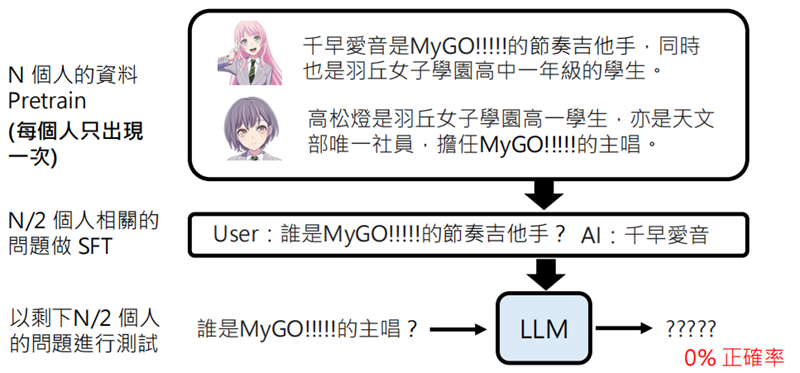
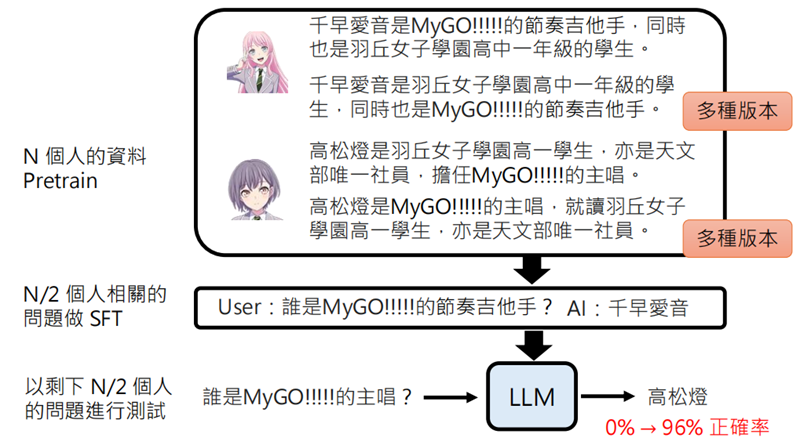
使用 N 个人的资料进行预训练,然后对 N/2 个人用相同的问题进行 SFT,用另外一半的人做测试,大模型并不能正确回答。但是如果我们在 Pretrain 时提供多重版本的资料,这时就可以得到较高的正确率
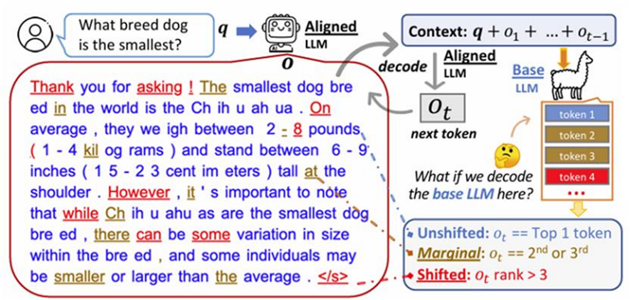
SFT 并没有给模型带来本质上的变化,观察 alignment 前后每个词输出概率的对比,分为三种,Unshift, Marginal, Shifted。
最后发现 alignment 生成出来的文案只有少部分是 Shifted 的,集中在一些连接词,以及结束词之类的
Pretrain 会留下一些痕迹:模型在Rot-13(移位13位)上解码准确率极高,而在其他移位(如Rot-8)上失败,这是因为预训练数据(如C4)中Rot-13内容出现频率远高于其他移位,导致模型“记住”了高频模式而非真正理解密码规则,其行为深受训练数据分布影响。

早期倾向为不同任务(翻译、摘要)训练专才模型;现在倾向于用涵盖 1800+ 种任务的混合资料训练一个通才模型(如 FLAN, InstructGPT, LLaMA2)。
资料在精不在多 (LIMA):研究发现,仅用 1000 条高品质、多样化的 SFT 资料,效果可能优于用 52k 条普通资料。
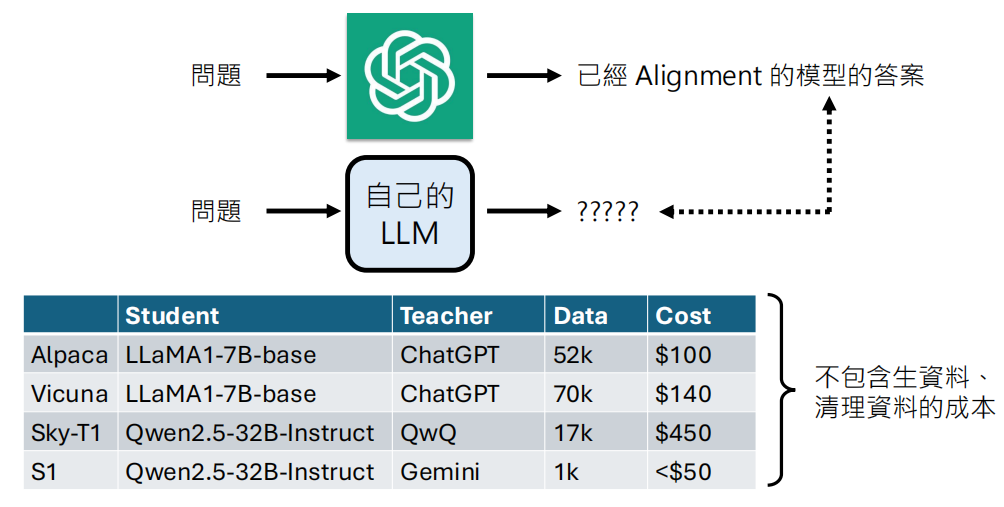
资料来源在早期常常使用人工标注,中期会使用更强的模型(如 ChatGPT)生成资料来训练较小的模型(知识蒸馏 Knowledge Distillation)
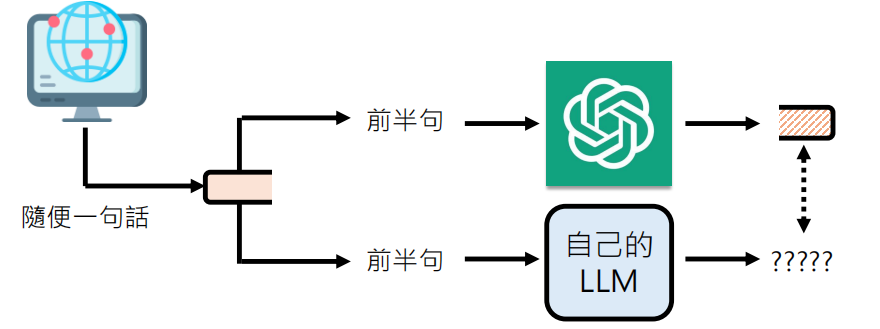
上面还需要问问题,我们也可以使用非指令微调(Non-instructional Fine-tuning),连问题都不需要问了。具体来说:首先从网络中选取“随便一句话”作为输入,将其“前半句”同时输入给一个强大的教师模型个待训练的学生模型,教师模型会生成标准的后半句,而学生模型则尝试生成自己的回答,通过让学生模型模仿教师模型的输出,从而将教师模型的知识迁移到学生模型中,以提升学生模型的生成能力。
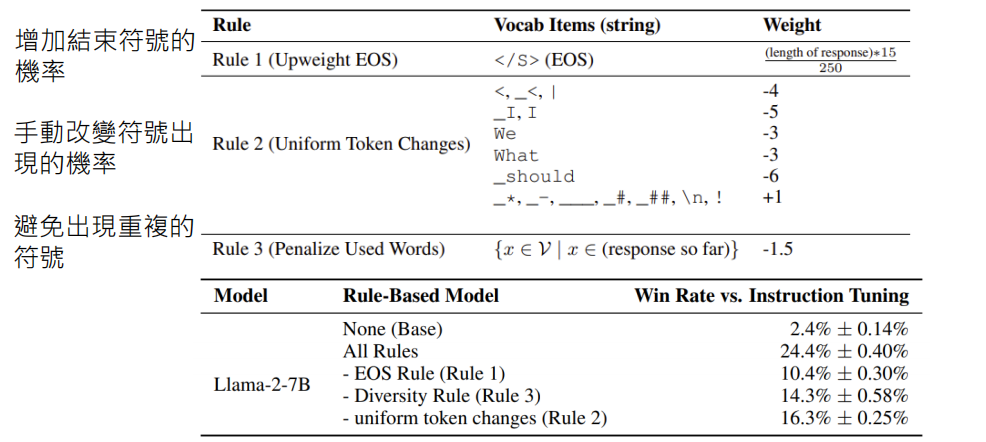
甚至发现有些模型在不经过传统 SFT 的情况下,仅通过调整结束符号概率也能展现指令遵循能力。
RLHF¶
学习方式是通过强化学习 (Reinforcement Learning),人类仅提供反馈(好/坏),不提供标准答案。
为什么需要 RLHF?
- SFT 虽然教会了模型回答,但无法保证回答的“质量”、“风格”或“安全性”。
- 人类撰写完美答案很累,但判断两个答案哪个更好很容易。RLHF 利用这种“批评比生成容易”的特性。
RLHF 与 SFT 对比
损失函数不同:
-
SFT:计算预测 Token 与标准答案 Token 之间的距离(Cross Entropy),每个 Token 都有明确的目标。
-
RLHF:基于整个回答获得的奖励(Reward)来更新模型。奖励是稀疏的(只在回答结束时给分),且无法直接计算梯度。
评估粒度:
- SFT:只问过程(每个字对不对)。即使只错一个字,也可能导致整句意思全非(如“我可以教你做坏事”vs“我不可以”),但在 SFT Loss 中可能只差一个 Token 的误差。
- RLHF:只问结果(整个回答好不好)。即使每个字都通顺,如果整体意图是坏的,奖励就是负的。
资料来源:
-
SFT:老师(人类)给的固定教材。
-
RLHF:模型自己生成的回答,由人类(或奖励模型)评分。这是一种“因材施教”,针对模型容易犯错的地方进行修正。
常用 Policy Gradient,PPO (Proximal Policy Optimization)、DPO (Direct Preference Optimization) 等算法,目的是最大化预期奖励。基本的思想如下:
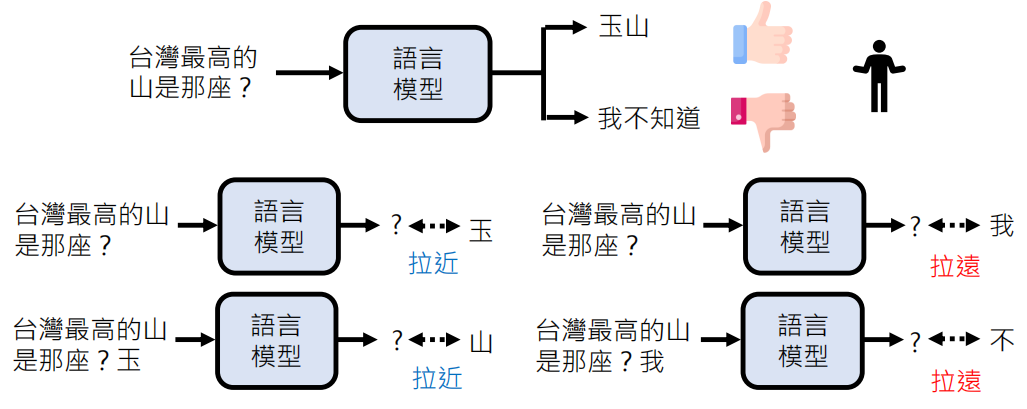
具体来说怎么实现,不在这里进行阐述。
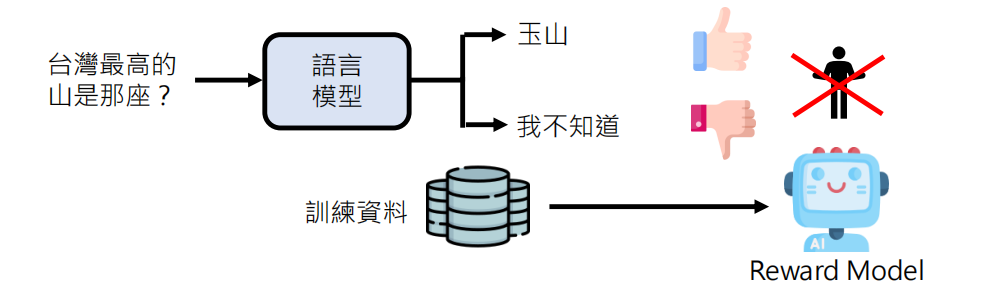
为了减少人类参与的成本,现在常使用另一个训练好的 AI 模型(Reward Model)来代替人类进行评分,称为 RLAIF (Reinforcement Learning from AI Feedback)。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!