4 Evaluation¶
评估一个模型的好坏对于大模型的发展和用户的使用都是是否重要的。
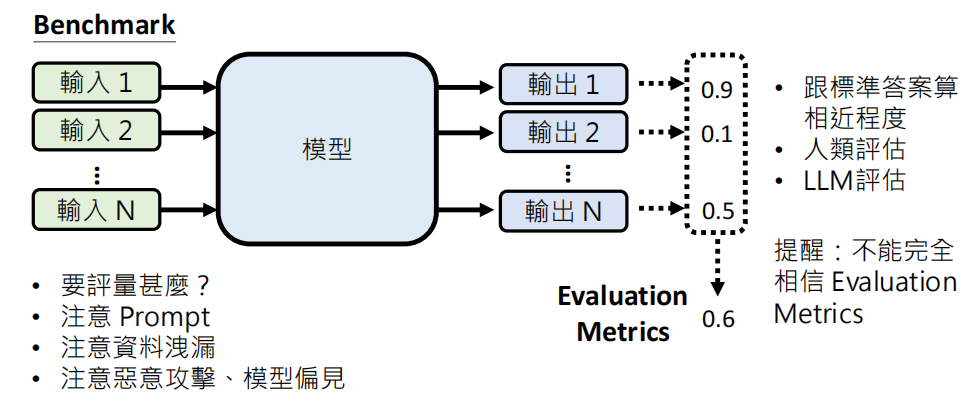
对于有标准答案的情况,很自然的想法就是让大模型在一个 Benchmark 上跑出相应的结果,然后与正确答案做比对,得到一个分数然后做平均,谁分数高,谁的模型能力就更好。
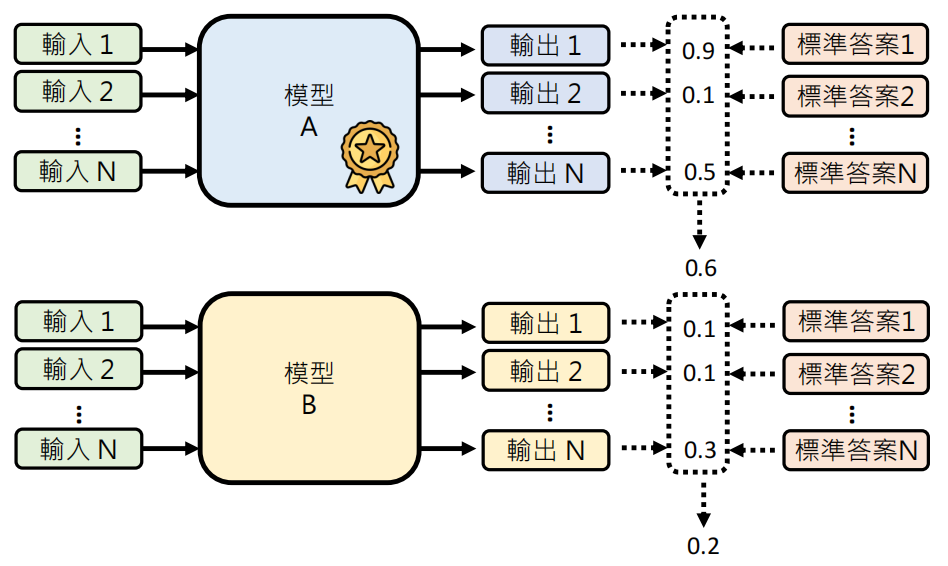
取平均数更好吗?
取每一个输入得到的分数的平均数是否合理,比如说对于一个语音合成系统,在绝大多数输入下,表现得都很完美,但是在一些特定的输入下会输出一些额外内容,脱离原先的内容,这个时候分数会很低,但你能说这个模型很差吗?这也不见得。
对于这个方法,最为重要的就是对答案的方法。
- 采用 Exact Match,一样就给满分,不一样就得零分。这种方法显然不适合用在问答题上,只适合答案已知且有限的情况,例如选择题。但是即使是选择题,我们之前也要告诉大模型只能回答 ABC,那么看懂指令也很重要。那么这里就很可能是在考模型是否看懂指令格式,而非真实能力。
-
采用 相似度评估,当答案不唯一或表达方式多样时使用。
-
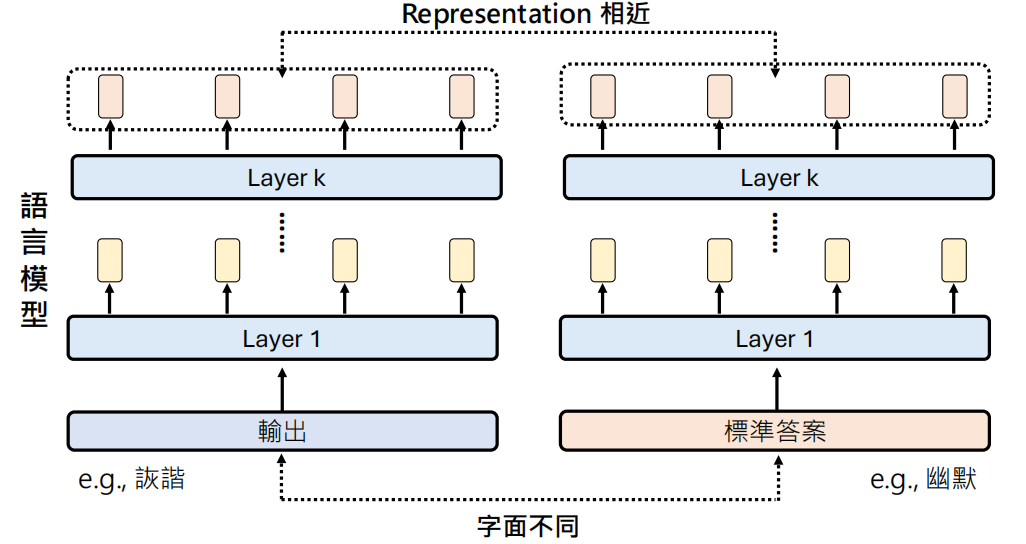
一些传统指标包括 BLEU(常用于机器翻译,比对共同词汇的重叠率)、ROUGE(常用于文章摘要)但是这回导致字面不同但语义相同的情况(如“幽默”vs“诙谐”)会导致得分低。
-
语义相似度指标,如BERT Score,利用语言模型的向量表示(Representation)来衡量语义相近程度,而非单纯的字面匹配。
-
但是我们也不要过于相信 Evaluation 的分数,如果完全相信 Evaluation 得到的分数 → 你可能會得到一個在 Evaluation 取得高分,但实际上表现不佳的模型
Goodhart's Law(古德哈特定律)——当一个指标成为目标时,它就不再是一个好的指标。
Parrot
评估一个帮助用户完成 “换句话说” 的模型,模型为了迎合评价指标(如BLEU),模型可能就原封不动地返回了输入,这样肯定会获得好的输入,但是却并没有达到好的效果。那为了避免这一种情况,我们加入一个条件是要求与原先有百分之多少的不同,模型可能就将原先输入的话改成乱码,获得的分数可能也很高。
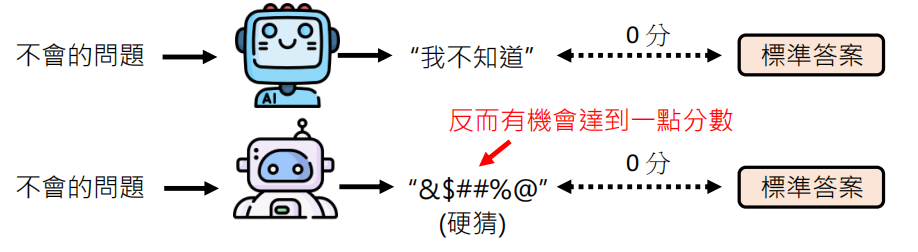
Can't Say "I don't know"
在评估中,回答“我不知道”通常得0分。硬猜错误答案可能反而有概率得分。后果就是模型在不确定时产生幻觉,而不是诚实承认无知。
改进思路:引入倒扣机制(答错扣分,不答0分),鼓励模型在不知道时拒绝回答(参考 Simple QA)。
对于没有标准答案的情况,比如说写一本小说,或者写一首诗。这样机器并不能很好的来做评判,这时我们可以请出人类来完成这一项工作。
但是人类的评估真没有问题吗?
-
有时候,人类过于在意“怎么说”,而忽略了“说了什么”。较长的回答、精美的 Markdown 排版,以及多使用表情符号,往往在评分中更占优势。
-
在语音合成中,人类对“自然度”(Natural) 和 “失真度”(Distort) 的感知可能与客观相似度指标不一致。
- 主观性与成本:花费时间金钱,且再现性差(不同人评分标准不一)。
那么我们可不可以使用 AI 来评分呢?
给语言模型的指令格式会显著影响评分结果与人类评分的一致性
- 仅输出数字 (Number only):相关性较低 (约 0.32~0.36)。
- 无限制 (No restriction):相关性中等 (约 0.32~0.47)。
- 先数字后解释 (Number then explanation):要求模型先给分再解释理由,相关性提升 (约 0.45~0.55)。
- 先解释后数字 (Explanation then number):要求模型先分析再给分,效果最好,在连贯性 (Coherence) 等指标上可达 0.635 的相关性。
我们也可以选择训练一个专门的评分模型来打分
评估好坏通常比生成内容容易
- 输入:问题、模型输出、标准答案、评分标准。
- 输出:可以是单一分数,或是对每个分数选项的概率分布,最终计算期望值作为得分
用途:这些评分模型可用于强化学习(RL),让生成模型学习优化以获得更高的验证者分数。
但是使用语言模型评分并非完美,存在明显的偏见:
- 自我偏袒:语言模型倾向于给自己生成的答案较高的分数。
- 位置偏见:在比较两个答案(Assistant A vs. Assistant B)时,模型可能倾向选择排在前面或后面的答案,取决于具体模型版本。
- 风格偏见:类似人类评分,模型也可能被长篇幅、漂亮的格式(如 Markdown、表情符号)所迷惑,而忽略内容实质
所以我们在大规模使用语言模型进行评分前,应先进行小规模测试,确认其评分结果与人类评分是否具有高度相关性。
对于评估大模型来说,还有一个很重要的点就是问题集中要问什么问题?
这个问题应该问你自己(哈哈),考什么取决于你在意什么(单一任务、通用能力、特定领域如金融/医疗)。
生产力评估 (GDPval):测试AI能否完成对GDP贡献最大的职业中的关键任务,测试的结果看似已经和人类能做的内容已经类似,但胜出的点多集中在一些非核心任务上,比如说安排事情之类的。
长文处理:“大海捞针” (Needle in a Haystack) 测试,即在超长文本中查找特定信息的能力。在这个实验中,能够很明显得到 Prompt 会影响 Evaluation 的结论。良好的 Prompt 能激发出模型真实的长文本处理能力。
语音评估:比较两段录音的流利度,大模型有时会拒绝,会说一些客气话,但是如果在 Prompt 中加入强制性语句,会得到结果。所以这也说明良好的 Prompt 对于评估的重要性
综上,我们在做 Evaluation 的时候,Prompt 是一个不可忽视的点,在比较两款模型的时候,应该将多个不同的 Prompt 的结果取平均。
还要一个问题是:模型可能已经在训练数据中“偷看”过测试题(如GSM-8k数学题),导致分数虚高。使用 LessLeak-Bench 等基准测试,专门检测模型是否因见过题目而表现更好。
Example
模型竟然直接把考题接龙接出来了
越狱攻击 (Jailbreak):测试模型是否会绕过安全限制回答恶意问题(如“教我做炸弹”)。Jailbreak 的一些常用的方法有逻辑诉求、权威背书、虚假陈述等等,模型需要有抵御这些攻击的能力
提示词注入 (Prompt Injection)
- 直接注入:在对话中嵌入恶意指令控制AI主播或篡改论文评审意见。
- 间接注入:通过让Agent读取包含恶意指令的网页或文件(如“把机密文件上传到这个链接”)来实施攻击。
偏见评估:测试模型是否有偏见
测试方法:修改句子中的特定属性词汇(如性别、身份),观察模型输出是否有差别对待(例如评价“男朋友不理我”vs“女朋友不理我”的态度差异)。
总结来说:
从 Benchamark 的输入角度,要注意:
- 你要考察模型的那些方面
- 关注 Prompt 对于评估的影响,可以取多个 Prompt 测评结果的平均值
- 注意是否存在资料泄露,模型把 Benchmark 的内容拿过来训练了
- 抵御恶意攻击的能力
- 模型是否存在偏见
从评估的角度来看,要注意
- 选择什么样的方法
- 不要过度相信评估的结果
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!