7 Blocks & Traces¶
IR 树不能直接翻译为汇编,因为树结构与线性机器指令之间存在三大不匹配。解决方案是一条三级流水线:线性化 (Linearize) → 基本块划分 (Basic Blocks) → 踪迹调度 (Trace Scheduling)。
7.1 Motivation: Three Mismatches¶
1. CJUMP 的双向性 — IR 的 CJUMP(cond, Ltrue, Lfalse) 同时指向两个标签,但机器指令只有"条件跳转"或"落空 (fall through)",一次只能跳一个方向。
2. ESEQ 的嵌套 — IR 中表达式内部可包含语句 ESEQ(s, e),存在计算顺序依赖,而机器指令是线性序列,没有嵌套语义。
3. CALL 的嵌套 — CALL 可以嵌套在外层调用的参数中(如 f(e1, g(e2))),直接展开会遇到两类问题:
- 副作用 (Side Effects):
g除返回值外可能修改全局变量、堆内存等。若e1依赖这些状态,g调用前后e1的值可能不同——而语言通常要求参数从左到右求值,e1必须在g之前计算。 - 寄存器冲突:
e1应放入外层调用的第一个参数寄存器,而g的返回值会放入返回值寄存器。在许多调用约定中,第一个参数寄存器和返回值寄存器是同一个(如 Tiger 编译器用rv兼做参数寄存器),即使先算了e1,g的调用也会覆盖它。
7.2 Linearization¶
目标是把树形 IR "拉直"为线性语句列表,分三步。
7.2.1 Eliminate ESEQ¶
核心是交换律分析——判断语句 s 和表达式 e 是否互相干扰:
BINOP(op, ESEQ(s, e1), e2)→ESEQ(s, BINOP(op, e1, e2))(总是成立,s在最左侧)BINOP(op, e1, ESEQ(s, e2))→ESEQ(s, BINOP(op, e1, e2))(仅当s与e1可交换)- 不可交换时:引入临时变量
MOVE(TEMP t, e1),将e1的计算提前到s之前,再在BINOP中用TEMP t替代
交换律条件:s 中写的变量(def)与 e1 中读/写的变量不重叠。
7.2.2 Move CALL to Top Level¶
每个 CALL 必须立即将结果存入新鲜临时变量:
这保证嵌套调用不会相互覆盖返回值寄存器——每个调用的结果各自存在独立临时变量中。
CALL 的嵌套
对 f(g(a), h(b)) 应用 Move CALL to Top Level——两个调用都嵌套在外层 f 的参数中。
转换前:
CALL(NAME f, [sl,
CALL(NAME g, [sl, TEMP a]), // 第一参数: 嵌套的 CALL
CALL(NAME h, [sl, TEMP b]) // 第二参数: 嵌套的 CALL
])
问题:两个内层 CALL 都往 rv 写返回值,后执行的覆盖先执行的,外层 f 无法同时拿到两个值。
转换思路:根据语义直接重写:参数从左到右求值,每个嵌套的 CALL 提出来存入临时变量,用临时变量替换原来的位置。最后外层调用本身也作为一个独立的 MOVE(TEMP, CALL(...)):
[1] MOVE(TEMP t1, CALL(NAME g, [sl, TEMP a])) // 先求第一参数 g(a) → t1
[2] MOVE(TEMP t2, CALL(NAME h, [sl, TEMP b])) // 再求第二参数 h(b) → t2
[3] MOVE(TEMP t3, CALL(NAME f, [sl, TEMP t1, TEMP t2])) // 最后调 f(t1, t2)
每个 CALL 独立成一条指令,结果存入各自的临时变量,顺序明确,寄存器互不覆盖。
7.2.3 Flatten SEQ¶
将嵌套的 SEQ(SEQ(a, b), c) 递归展开为平铺列表 [a, b, c]。至此 IR 树变为无嵌套的线性指令序列。
Example — 对 x = (y := y + 1; y) * f(z) 执行完整的线性化流程。
源码含义:先将 y 自增,表达式 (y := y + 1; y) 的值为新 y;再乘以 f(z) 的返回值。
原始 IR 树:
MOVE(TEMP x, // x =
BINOP(MUL, // *
ESEQ( // ( ← ESEQ: 先执行赋值, 再返回 y
MOVE(TEMP y, BINOP(PLUS, TEMP y, CONST 1)),
TEMP y),
CALL(NAME f, [sl, TEMP z]))) // f(z) ← CALL 嵌套在 BINOP 内
Step 1 — Eliminate ESEQ:ESEQ 在 BINOP 左侧,总是可交换 → 直接提出:
BINOP 右侧只剩 CALL,无 ESEQ 需要处理。
Step 2 — Move CALL to Top Level:CALL 位于 BINOP 内,引入临时变量 t 保存调用结果:
ESEQ(
MOVE(TEMP y, BINOP(PLUS, TEMP y, CONST 1)),
ESEQ(
MOVE(TEMP t, CALL(NAME f, [sl, TEMP z])),
BINOP(MUL, TEMP y, TEMP t)))
Step 3 — Flatten SEQ:外层 MOVE(TEMP x, ...) 包裹两步 ESEQ,展开为嵌套 SEQ 再展平:
MOVE(TEMP x, ESEQ(MOVE(..., ...), ESEQ(MOVE(..., ...), BINOP(...))))
↓ 展开 SEQ
SEQ(MOVE(TEMP y, BINOP(PLUS, TEMP y, CONST 1)),
SEQ(MOVE(TEMP t, CALL(NAME f, [sl, TEMP z])),
MOVE(TEMP x, BINOP(MUL, TEMP y, TEMP t))))
↓ 展平
[1] MOVE(TEMP y, BINOP(PLUS, TEMP y, CONST 1))
[2] MOVE(TEMP t, CALL(NAME f, [sl, TEMP z]))
[3] MOVE(TEMP x, BINOP(MUL, TEMP y, TEMP t))
三条线性指令保留了原始语义:先自增 y,再调用 f(z) 并存入 t,最后乘起来赋给 x。
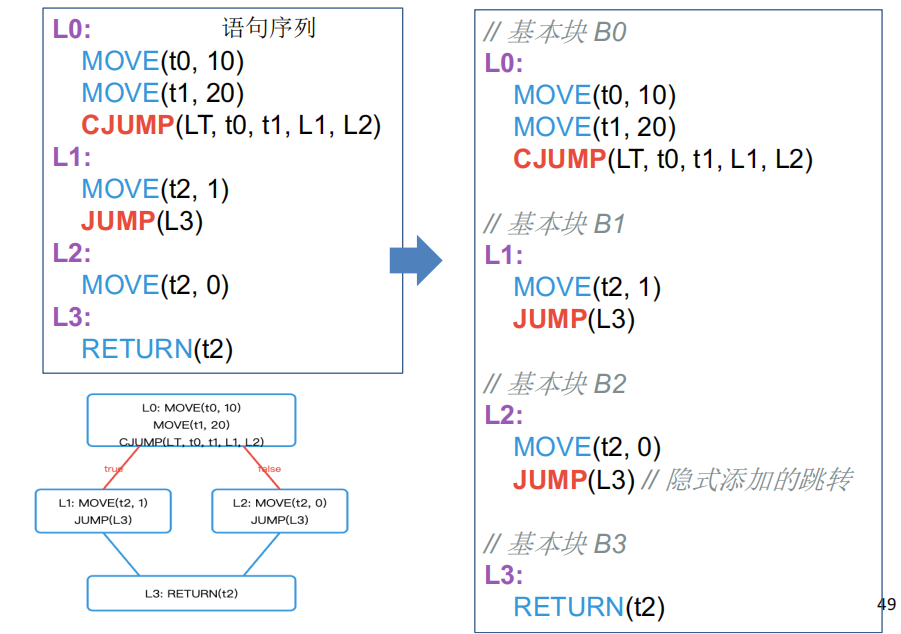
7.3 Basic Blocks¶
将线性指令列表切分为基本块——一个入口在开头(以 LABEL 开始)、出口在结尾(以 JUMP 或 CJUMP 结束)的语句序列,内部不含任何标签或跳转。
构建算法:
- 扫描线性列表。
- 遇到
LABEL→ 开启新块(结束前一个块)。 - 遇到
JUMP/CJUMP→ 结束当前块。 - 修复:不以
LABEL开头的块补一个标签;不以跳转结尾的块补JUMP到后继块。
控制流图 (CFG):节点 = 基本块,边 = 跳转关系。后继 succ 和前驱 pred 关系构成后续数据流分析的基础。
7.4 Trace Scheduling¶
基本块划分后需要重排顺序以优化生成的汇编。
动机:减少冗余跳转,利用 CPU 的 fall-through 特性(条件不成立时顺序执行下一条,无需显式跳转),提升指令缓存局部性。
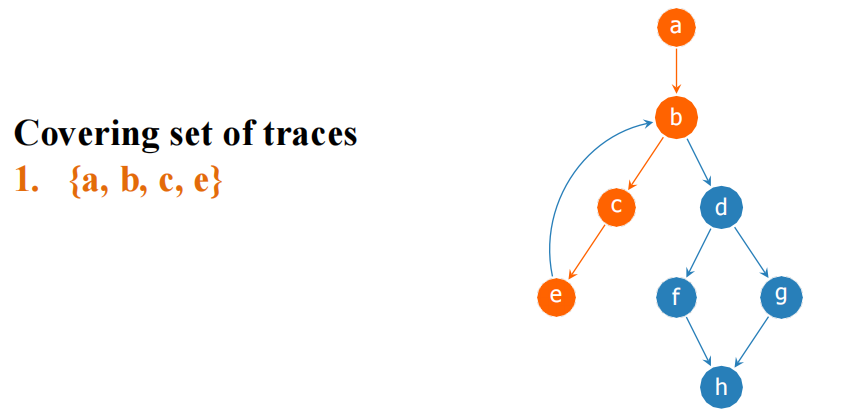
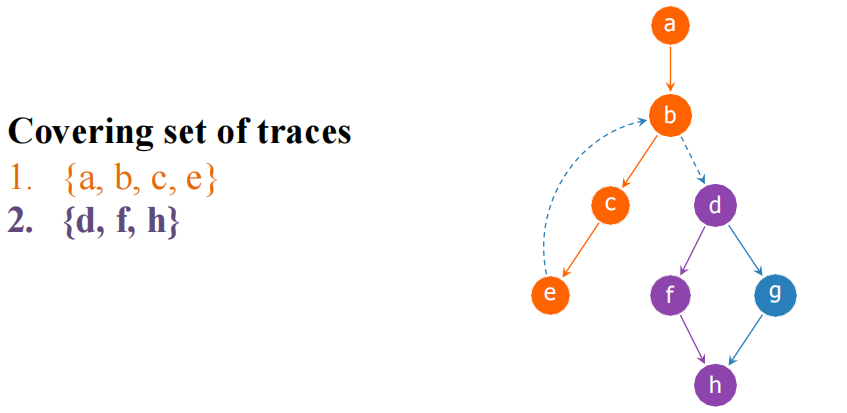
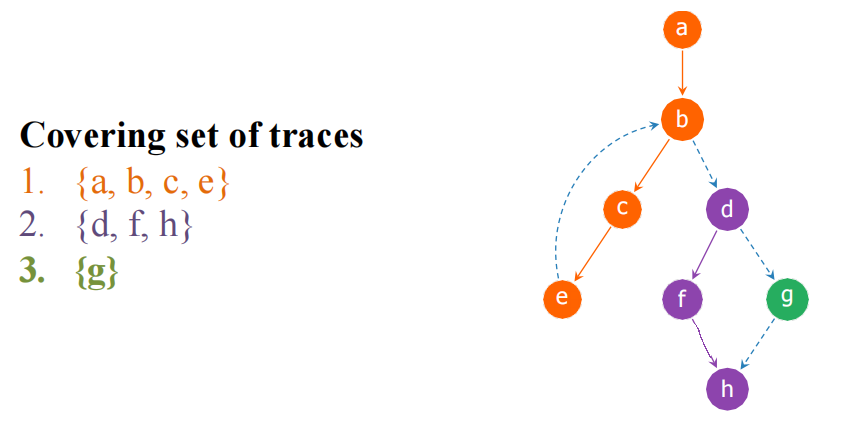
Trace:一个可能连续执行的基本块序列。覆盖集是一组 Trace,包含所有基本块且每个块恰好出现一次。
贪心生成算法:
- 选一个未标记的块作为 Trace 起点。
- 沿 CFG 边尽量"拉入"后继块,标记为已访问,直到后继已被标记(属于其他 Trace)或路径结束。
- 重复直到所有块被覆盖。
Example
收尾修复:确保每个 CJUMP 的 false 分支紧跟其后(利用 fall-through):
- 若
CJUMP后跟的是 True 标签 → 交换 true/false 标签,取反条件。 - 若
CJUMP后跟的都不是 ,则可以如下变化
CJUMP(>, x, y, Lt, Lf)
...other code...
变成
CJUMP(>, x, y, Lt, L’f)
LABEL L’f
JUMP(Lf)
...other code...
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!