11 Garbage Collection¶
垃圾回收 (Garbage Collection, GC) 是运行时系统自动回收不再使用的堆内存的机制,将程序员从手动 free/delete 中解放出来。核心问题是:判定哪些对象是"垃圾"(不再可达),然后安全高效地回收它们。
11.1 Overview¶
手动内存管理有三个经典痛点:
- Double Free:对同一块内存多次释放,可能破坏分配器内部结构导致崩溃。
- Memory Leak:忘记释放不再使用的内存,长期运行下耗尽堆空间。
- Fragmentation:频繁分配/释放不同大小的块,产生大量小空闲碎片,即使有足够的空闲总量也无法满足大块分配请求。
GC 通过自动判定对象是否"可达"并回收不可达对象,从根本上消除了前两个问题,部分算法还能缓解碎片化。
11.1.1 Reachability¶
垃圾 (Garbage):已分配但不再被程序访问的堆对象。
可达性 (Reachability):从一组根节点 (Roots) 出发,沿指针追踪到的所有对象都是可达的。根节点包括:
- 寄存器中存储的指针值
- 栈上的局部指针变量
- 全局/静态变量中的指针
GC 的核心工作就是从 Roots 出发遍历对象图,标记所有可达对象,然后回收不可达对象。
11.1.2 Conservative Approximation¶
理论上,精确判定"一个对象是否将来还会被使用"等价于停机问题,不可判定。因此 GC 采用保守近似:
不可达 \(\Rightarrow\) 垃圾(安全,不会误回收)
可达 \(\Rightarrow\) 非垃圾(保守,可能保留了一些"可达但永远不会再被使用"的对象)
这种近似保证了 GC 的安全性——绝不在对象还被引用时就回收其内存。
11.1.3 Ideal GC Metrics¶
| 指标 | 含义 |
|---|---|
| 安全 (Safety) | 绝不回收可达对象 |
| 完全 (Completeness) | 回收所有垃圾对象 |
| 低开销 (Low Overhead) | GC 本身不显著拖慢程序 |
| 短暂停 (Short Pause) | 不造成明显的程序停顿 |
| 空间效率 (Space Efficiency) | 不浪费过多内存 |
| 并行性 (Concurrency) | 可与用户程序并发执行 |
没有单一算法在所有指标上最优,实际系统常组合多种策略(如分代 GC)。
11.2 Mark-and-Sweep¶
标记-清除是最经典的 GC 算法,分两个阶段。
Phase 1 — Mark:从 Roots 出发做 DFS 遍历,标记所有可达对象(通常在对象头中设一个 mark bit)。
Phase 2 — Sweep:线性扫描整个堆。未标记的对象回收到空闲链表 (Free List);已标记的对象清除标记位,为下一轮 GC 做准备。
11.2.1 Mark Phase: Pointer Reversal¶
Mark 阶段的 DFS 面临一个实现难题:对象图可能非常深,递归 DFS 会栈溢出。解决方案有二:
方案 1 — 显式栈:手动维护一个栈结构(放在堆上),将递归改为迭代。缺点是额外内存开销大。
方案 2 — 指针反转 (Pointer Reversal):最经典的技术,无需额外栈空间。核心思想是借用对象自身的指针字段来记录回溯路径。
function DFS(x)
// 入口检查:x 必须是指针且未被标记
if x is a pointer and record x is not marked
t ← nil // t 始终指向当前节点 x 的父节点
mark x; done[x] ← 0 // done[x] 记录 x 已处理到第几个字段
while true
i ← done[x] // 当前正在检查第 i 个字段
if i < # of fields in record x
// —— 情况 1:x 还有未处理的字段 ——
y ← x.fi // 取出 x 的第 i 个字段
if y is pointer and record y not marked
// y 是未访问的子节点 → 前进 (down)
x.fi ← t // ★ 指针反转: 让字段指回父节点 (记录回溯路径)
t ← x // 旧当前节点成为新的父节点
x ← y // 进入子节点
mark x; done[x] ← 0 // 标记并初始化新节点
else
// y 不是有效子节点 → 跳过,处理下一字段
done[x] ← i + 1
else
// —— 情况 2:x 所有字段已处理完 → 回溯 (up) ——
y ← x // 保存已完成的节点 (待恢复使用)
x ← t // 沿反转指针回到父节点
if x = nil then return // 回到根以上 → 遍历完成
i ← done[x] // 查父节点当初是从第几个字段下去的
t ← x.fi // 暂存父节点这个字段当前的值 (即指向祖父的反转指针)
x.fi ← y // ★ 指针恢复: 将这个字段改回原来的值 (指向子节点)
done[x] ← i + 1 // 该字段已恢复,跳到下一个字段
关键在于:每一步只反转一个指针(指向其父节点),其余字段保持不变。回溯时原路恢复。Deutsch-Schorr-Waite 算法将"在哪里""怎么回去"的信息编码在对象自身的字段中,实现了零额外空间的图遍历。
11.2.2 Sweep Phase¶
Sweep 阶段从堆底到堆顶线性扫描每个对象:
cursor = heap_start
while cursor < heap_top:
if cursor.marked:
cursor.marked = false // 清标记,为下次 GC 准备
else:
add_to_free_list(cursor) // 回收
cursor += object_size(cursor)
这里 object_size(cursor) 需要从对象头中获取——每个堆对象通常包含一个 header 记录其大小和标记位。
11.2.3 Fragmentation¶
Mark-Sweep 的主要缺点是外部碎片 (External Fragmentation):
- 回收的对象形成零散的空闲块,散布在堆中各处
- 小空闲块总和可能很大,但单个都不够满足大分配请求
- 分配时需要遍历空闲链表找合适大小的块(first-fit / best-fit),效率随碎片增多而下降
与碎片相关的还有内部碎片 (Internal Fragmentation):空闲链表中的块可能略大于请求大小,多余字节浪费在当前分配中。
11.2.4 Evaluation¶
| 评价 | |
|---|---|
| 优点 | 处理循环引用;对象不移动(C/C++ 友好) |
| 缺点 | 需暂停程序(Stop-the-World);产生碎片;扫描整个堆,效率随堆大小增长而下降 |
11.3 Reference Counting¶
引用计数的思路与 Mark-Sweep 完全不同:每个对象维护一个引用计数器,记录当前有多少个指针指向它。计数器降为 0 时立即回收。
11.3.1 Mechanism¶
基本操作:
新增引用 (new_ref): obj->rc++
删除引用 (del_ref): obj->rc--
if obj->rc == 0:
释放 obj
for each 字段 f in obj where f 是指针:
del_ref(f) // 递归回收
每次指针赋值 x = y 时,底层需要执行:
编译器会在每次指针写入操作前后自动插入这些计数更新代码。
11.3.2 Cycles¶
引用计数的致命缺陷:无法回收循环引用结构。
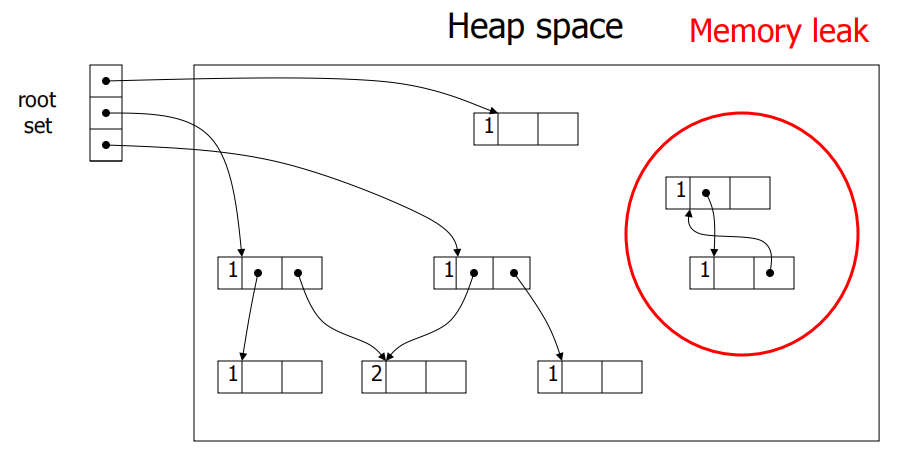
这个问题在链表、树、图等常见数据结构中经常出现。解决方案包括: - 弱引用 (Weak Reference):不计入引用计数,打破循环 - 混合策略:周期性运行 Mark-Sweep 回收循环垃圾,日常使用引用计数
11.3.3 Performance Overhead¶
引用计数的主要开销来自每次指针赋值都必须更新计数。原本一条 x.fi ← p 的机器指令,在引用计数下需要展开为对旧目标和新目标的两次计数更新:
// 原始语义: x.fi ← p
// 实际执行:
z ← x.fi // ① 取出旧值
c ← z.count // ② 读旧引用计数
c ← c - 1 // ③ 递减
z.count ← c // ④ 写回
if c = 0 then
putOnFreelist(z) // ⑤ 计数归零则回收
x.fi ← p // ⑥ 执行赋值
c ← p.count // ⑦ 读新引用计数
c ← c + 1 // ⑧ 递增
p.count ← c // ⑨ 写回
一次指针赋值从 1 条指令膨胀为 7~9 条(含条件分支),频繁执行时开销显著。再加上计数器每次更新都需要读写内存(z.count、p.count),进一步加剧了 cache 压力。
惰性计数 (Deferred Reference Counting) 是主要优化手段。核心思路:栈上变量的变更极其频繁(每次函数调用、每次 let 都产生新绑定),每次都去更新堆对象的计数器代价太大。惰性计数跳过栈引用的计数更新,只跟踪堆对象之间的引用;GC 时再统一扫描栈来"补票"。
对比标准 RC 与惰性 RC 在以下代码中的行为
let
var a := new Point{x=1, y=2} // 堆分配 Point#1, rc 初始 = 0
var b := new Point{x=3, y=4} // 堆分配 Point#2, rc 初始 = 0
in
a := new Point{x=5, y=6}; // 分配 Point#3; a 改为指向 Point#3
b := a; // b 也指向 Point#3
print(b.x)
end
标准 RC 执行过程(每次栈变量赋值都更新计数):
// a := new Point#1
a ← Point#1 rc(Point#1): 0→1 ← 栈变量 a 引用 +1
// b := new Point#2
b ← Point#2 rc(Point#2): 0→1 ← 栈变量 b 引用 +1
// a := new Point#3
old ← a 取出旧值 Point#1
old.rc: 1→0 a 不再指向 Point#1
if rc=0 → free #1 ★ Point#1 被立即回收
a ← Point#3 rc(Point#3): 0→1
// b := a
old ← b 取出旧值 Point#2
old.rc: 1→0 b 不再指向 Point#2
if rc=0 → free #2 ★ Point#2 被立即回收
b ← Point#3 rc(Point#3): 1→2 ← b 也指向 #3, 计数再 +1
// 退出 let, a 和 b 出作用域
a, b 出栈 → rc(Point#3): 2→1→0 → free #3
每次栈变量的赋值、出作用域都触发计数更新,代码中总共触发 ~10 次 RC 操作。
惰性 RC 执行过程(栈引用不计入计数):
// 正常运行期间 — 栈变量的读写不碰计数器!
a ← Point#1 rc(Point#1): 0 (不变! 因为 a 是栈变量)
b ← Point#2 rc(Point#2): 0 (不变!)
a ← Point#3 不更新任何计数 (a 从栈变量 #1 改为 #3, 不触发 free)
b ← a 不更新任何计数
// ★ 到这里, 三个 Point 的 rc 都是 0!
// 如果此刻触发 GC, 扫描栈会发现 a,b 指向 Point#3,
// 临时将 rc(Point#3) 加回 → Point#3 存活, Point#1,#2 回收
惰性 RC 在正常运行中完全跳过了栈引用的计数更新——代码中0 次 RC 操作。GC 触发时才统一扫描栈帧,把当前栈变量的引用一次性"补记"到对应对象的计数器上,然后做常规的计数归零回收。
代价:垃圾回收被延迟。Point#1 在 a := Point#3 后就变成垃圾了,但因为没有立即触发计数归零,它一直留在堆上,直到下一次 GC 扫描栈时才发现已经没有栈变量指向它了。
11.3.4 Evaluation¶
| 评价 | |
|---|---|
| 优点 | 增量回收(无长暂停);实现简单;对象死亡时立即回收 |
| 缺点 | 循环引用导致内存泄漏;每次指针修改都有计数开销;计数器占用对象头空间 |
11.4 Copying Collection¶
拷贝收集将可用内存一分为二:From-space 和 To-space。用户程序只在 From-space 中分配。GC 时将所有存活对象从 From-space 复制到 To-space,然后交换两个空间的角色。
11.4.1 Semi-space Model¶
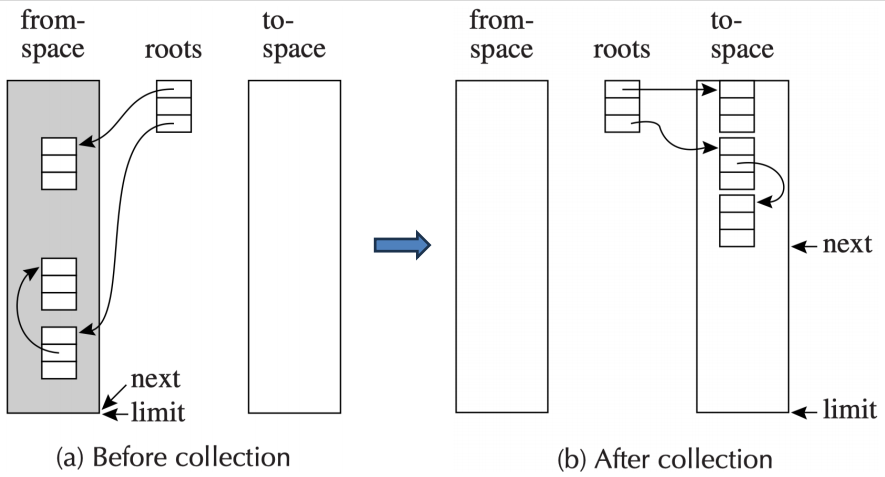
分配:新对象分配在 From-space 的顶端,使用指针碰撞 (Bump Pointer) —— 只需一条指令 p = from_ptr; from_ptr += size,极其快速。
回收:只复制存活对象到 To-space,垃圾自然被抛弃。然后整个 From-space 被整体重置,不存在碎片问题。
代价:50% 内存空间浪费(一半永远空闲)。
11.4.2 Cheney’s Algorithm¶
Cheney 算法是拷贝收集的经典实现,使用广度优先 (BFS) 遍历,仅需两个指针 scan 和 next 即可完成全部工作——无需显式队列或栈。
To-space 的三个区域:
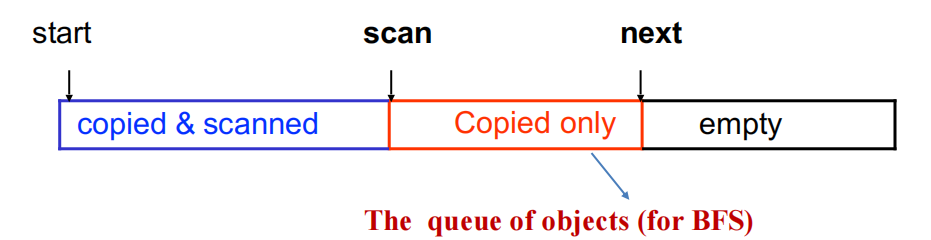
[to_start, scan):已扫描区——对象已被复制且其内部指针字段已全部处理完。[scan, next):已复制未扫描区——对象已复制到此,但其内部指针字段尚未处理。这个区域天然构成了一个 BFS 工作队列。[next, to_end):空闲区——下一个被复制的对象将放置于此。
Forward(p) 函数:负责将单个对象从 From-space 复制到 To-space,并处理指针转发。
function Forward(p):
if p 指向 From-space:
if p.f₁ 指向 To-space: // 已复制过, p.f₁ 是 forwarding pointer
return p.f₁ // 直接返回新地址
else:
// 复制到 next
for each field fᵢ of p:
next.fᵢ ← p.fᵢ // 逐字段复制到新位置
p.f₁ ← next // ★ 在原对象头留 forwarding pointer
next ← next + size(p) // 空闲指针前移
return p.f₁
else:
return p // 不是 From-space 指针, 原样返回
关键点:p.f₁ 被复用为 forwarding pointer——复制完成后,旧对象的第一个字段被覆写为新地址。后续任何指向该旧对象的指针再次调用 Forward() 时,看到 p.f₁ 指向 To-space,直接返回新地址,不会重复复制。
主算法:
scan ← next ← to_start // 初始: 两个指针都指向 To-space 起点
// Step 1: 复制根可达对象
for each root r:
r ← Forward(r) // 复制根对象, 更新根指针
// Step 2: BFS 扫描
while scan < next: // 队列非空 → 还有未扫描对象
for each field fᵢ of record at scan:
scan.fᵢ ← Forward(scan.fᵢ) // 复制子对象, 更新该字段指针
scan ← scan + size(scan) // 当前对象扫描完毕, 出队列
工作队列机制是理解 Cheney 算法的核心:
- 入队 (复制):
Forward()将对象复制到next处,next前进 → 对象进入[scan, next)区间。 - 出队 (扫描):
scan指向的对象被逐字段处理完毕后,scan前进 → 该对象退出队列。 - 终止条件:
scan == next→ 队列为空 → 所有可达对象已复制并扫描完毕 → GC 完成。
Example
-
A is the root; it has two pointer fields → B and C
-
B and C have no outgoing references
-
D is unreachable from the root
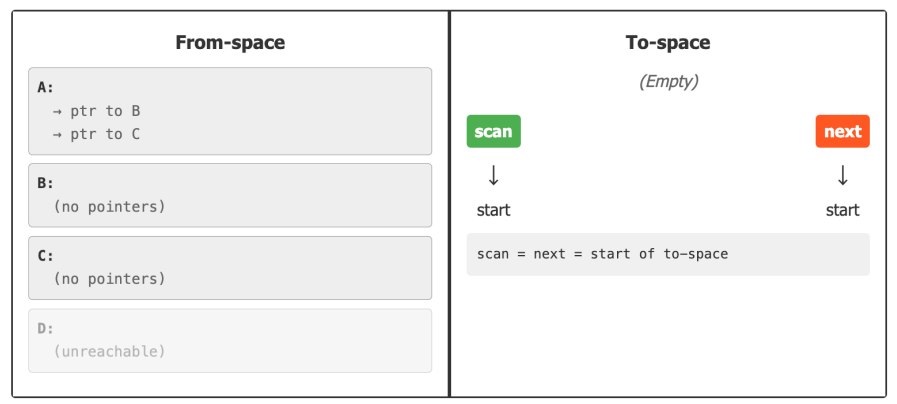
First, we copy the root object (A) to to-space and leave a forwarding pointer in the original object.

A’ is copied but not yet scanned ( its fields still hold the original from-space addresses of B and C.)
while scan < next: scan is at A, (process the object at scan (A') by forwarding its pointers to to-space.)

B' is now copied and scanned. C' is copied but not yet scanned.
Now we process the object at scan (B') by forwarding its pointers to to-space

B' is now copied and scanned. C' is copied but not yet scanned
Now we process the object at scan (C') by forwarding its pointers to to-space.
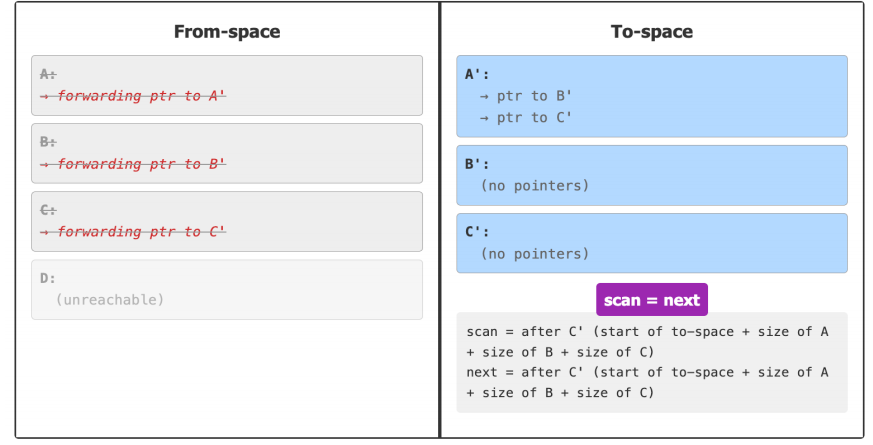
At this point, scan = next, which means we've processed all reachable objects and the collection is complete!
整个过程不需要额外栈或队列结构——[scan, next) 区间本身就是 BFS 队列。这就是 Cheney 算法的优雅之处。
11.4.3 Locality¶
Cheney 算法的 BFS 遍历缓存局部性较差。原因在于:CPU 从地址 a 取数据后,硬件会自动预取附近 cache line。如果相关对象在内存中距离很远,每次指针解引用都会触发 cache miss——这对 GC 扫描阶段尤为致命。
BFS vs DFS 的局部性差异:
对象图: A
/ \
B C
/ \
D E
BFS 复制顺序: A → B → C → D → E
- B 和 C 紧挨 → 好
- 但 D 和 E 离 C 远 → 访问 D,E 时 cache miss
DFS 复制顺序: A → B → D → E → C
- 父节点紧挨子节点 → 沿子树访问时数据已在 cache 中
- 局部性更好
DFS 复制的局部性更好,但需要额外栈(回到 Mark-Sweep 的栈溢出问题)。实践中 Cheney BFS 因其实现简单、无需额外栈而被广泛采用。
Hybrid Algorithm (混合算法):折中方案——在拷贝收集的大框架下混合 BFS 和 DFS。例如:用 BFS 机制管理 To-space(无需显式栈),但扫描一个对象时优先追踪它的子对象(即当前对象复制完成后,紧接着复制它的子对象而非兄弟对象),模拟 DFS 的顺序。这种"部分深度优先 (partly depth-first, partly breadth-first)"的策略在保留 Cheney 算法双指针简洁性的同时,改善了 cache 局部性。
Moon's Approximately Depth-First Algorithm:维护一个小容量的"近期复制对象"缓冲,优先从缓冲中选取下一个待扫描的对象。由于这些对象刚刚被复制、仍在 cache 中,可以显著减少 cache miss。当缓冲为空时再回退到正常 BFS 扫描。
11.4.4 Evaluation¶
| 评价 | |
|---|---|
| 优点 | 无碎片;分配极快(指针碰撞);只扫描存活对象(垃圾多时优于 Mark-Sweep);压缩对象提升局部性 |
| 缺点 | 50% 空间浪费;需移动对象(不适合 C/C++);Stop-the-World |
11.5 Interface to the Compiler¶
编译器需要为运行时 GC 提供关键支持。一个高效的 GC 系统是编译器和运行时紧密协作的结果。
11.5.1 Fast Allocation¶
在拷贝收集的半空间模型下,分配可以优化到几条机器指令:
// 上界检查 + 指针碰撞分配
r1 = limit // 当前空间上限
r2 = alloc_ptr // 分配指针
r3 = r2 + size // 新分配后的指针
if r3 > r1: goto gc_slow_path // 空间不够 → 触发 GC
alloc_ptr = r3 // 更新分配指针
return r2 // 返回新对象地址
关于 GC 触发时机:可以看到一旦当前空间不够了就触发 GC,这就是所谓"批处理检查"。快速路径只需三条指令(add + compare + branch),如果上界检查通过则直接返回。
Tiger 编译器中常见的优化:将多次小分配的边界检查合并为一次"预检查"——事先确保有 N 个对象大小的空间,然后连做 N 次无检查分配。
11.5.2 Type Descriptors¶
GC 需要知道每个对象的大小和哪些字段是指针(否则无法正确遍历对象图)。编译器为每个类型生成类型描述符 (Type Descriptor):
// 对于 Tiger 类型 {x: int, next: treelist}
// 类型描述符包含:
// - size: 对象的字节数
// - pointer_map: 哪些偏移处是指针
// 例如 bit 0 = 字段 0 是指针? (x: int → 否)
// bit 1 = 字段 1 是指针? (next: treelist → 是)
// → pointer_map = 0b10
当 GC 遍历一个对象时,查询其类型描述符,按 pointer_map 指示的偏移去追踪每个指针字段。
11.5.3 Pointer Maps (Root Maps)¶
GC 还需要精确知道当前栈帧和寄存器中哪些值是指针。编译器在GC 安全点 (Safe Point) 生成指针映射 (Pointer Map):
- GC 安全点通常设在分配点和函数调用点(这些位置可能触发 GC)。
- 指针映射精确记录:哪个寄存器存着指针、哪个栈槽存着指针。
- GC 发生时,用当前 PC 查表得到对应的指针映射 → 从寄存器和栈中提取所有根指针 → 开始遍历。
指针映射示例 (概念):
pc = 0x4040 (函数 f 中某安全点)
reg_map: R1=ptr, R2=ptr, R3=int, R4=int, ...
stack_map: [fp+8]=ptr, [fp+16]=int, [fp+24]=ptr, ...
11.5.4 Derived Pointers¶
派生指针 (Derived Pointer) 是指向对象内部的指针,而非指向对象头。
var arr := int[10] // arr 指向数组对象的头部
var p := &arr[5] // p 是派生指针, 指向数组内部
// GC 移动了 arr 指向的对象后:
// arr → 新位置 (对象头)
// p 需要更新为: 新对象首地址 + 原偏移量
GC 移动对象时(如在拷贝收集中),所有指向该对象的指针都需要更新为新地址。对于派生指针:
- 指针映射中标记该寄存器/栈槽持有派生指针,并记录其基指针所在位置。
- GC 移动对象后,基指针被更新为新对象首地址。
- 派生指针 = 新对象首地址 + (旧派生指针 - 旧对象首地址),即保持原偏移量不变。
编译器的一个重要职责就是正确标注哪些是指针、哪些是派生指针(如从数组索引 arr[i] 的地址计算产生的指针),否则 GC 将无法找到对象头。
11.6 Comparison¶
| Mark-and-Sweep | Reference Counting | Copying Collection | |
|---|---|---|---|
| 回收时机 | 批量 (Stop-the-World) | 实时 (对象计数归零) | 批量 (Stop-the-World) |
| 碎片 | 外部碎片 | 依赖分配器 | 无碎片 |
| 循环引用 | 可处理 | 无法处理 | 可处理 |
| 对象移动 | 否 | 否 | 是 (需更新所有指针) |
| 空间开销 | 最小 | 每对象一个计数器 | 50% 空间浪费 |
| 分配速度 | 中等 (空闲链表) | 中等 | 极快 (指针碰撞) |
| 适用场景 | C/C++ (Boehm GC) | Swift/Objective-C | 函数式语言 (ML, Haskell) |
现实世界中,高性能 GC(如 JVM 的 G1、ZGC)常采用分代收集 (Generational GC)——将堆分为年轻代和老年代,年轻代用拷贝收集(大部分对象朝生夕死,复制代价低),老年代用 Mark-Sweep/Compact,综合各算法的优势。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!