4 Semantic Analysis¶
语义分析是编译器前端最后一个阶段,建立在语法分析生成的 AST 之上,负责检查程序的深层语义是否合法——名字是否已声明、类型是否匹配、作用域是否正确——并为后续的中间代码生成做准备。
4.1 Overview¶
语义分析建立在 AST 之上,通过遍历 AST 节点检查程序含义。与语法分析处理"结构是否正确"不同,语义分析回答"含义是否合法"。
核心任务:
- 名字解析 (Name Resolution):将标识符的使用点连接到其声明点。例如变量
x出现在表达式中,需要找到它是在哪个var或let中声明的。 - 类型检查 (Type Checking):验证表达式的类型是否与上下文兼容。如
if条件必须是整型,+两边必须是同类型等。 - 作用域管理 (Scope Management):遵循语言的块结构和嵌套规则,确保内层声明遮蔽外层同名声明。
- 翻译 (Translation):将富语义的 AST 降级为结构更简单的中间表示 (IR),供后端使用。这一部分在 Tiger 编译器中体现为将 AST 翻译为 IR Tree。
与语法分析的关系:
| 语法分析 | 语义分析 | |
|---|---|---|
| 输入 | Token 流 | AST |
| 理论基础 | 上下文无关文法 (CFG) | 类型系统 / 属性文法 |
| 处理对象 | 结构 (句子形式) | 含义 (名字、类型) |
| 能否检测 | 括号不匹配 | 变量未声明、类型不匹配 |
| 不能检测 | int x = "hello" (结构合法) |
— |
语义分析的核心数据结构是符号表 (Symbol Table),核心算法是 AST 的递归遍历 + 类型推导。
4.2 Symbol Table¶
符号表是语义分析的基础设施,用于实现环境 (Environment)——将名字映射到其属性(类型、作用域层级、内存偏移等)的数据结构。
4.2.1 Formal Definition of Environment¶
环境 \(\Gamma\) (Gamma) 是一个从名字到绑定的部分函数:
\(\Gamma : \text{Name} \rightharpoonup \text{Binding}\)
其中 Binding 包含该名字的全部语义信息:
核心接口:
| 操作 | 签名 | 语义 |
|---|---|---|
insert |
insert(Γ, name, binding) → Γ' |
在 Γ 中新增绑定,返回新环境 |
lookup |
lookup(Γ, name) → Binding |
查找名字在当前环境中的绑定 |
beginScope |
beginScope(Γ) → Γ |
进入新作用域 |
endScope |
endScope(Γ) → Γ |
退出当前作用域,恢复外层环境 |
beginScope / endScope 可以嵌套——进入内层作用域后 insert 的绑定只在该作用域内可见,退出后自动失效。
4.2.2 Imperative Implementation¶
核心思想:维护一张可变哈希表 + 一个辅助栈。哈希表保证 \(O(1)\) 查找;栈记录每次 insert 操作,用于 endScope 时回滚。
数据结构:
HashTable symtab; // name → Binding
Stack<Symbol*> scopeStack; // 记录作用域内插入的名字 + 作用域标记
void beginScope() {
scopeStack.push(SCOPE_MARKER); // 压入作用域边界标记
}
void insert(string name, Binding info) {
symtab[name] = info; // 插入哈希表 (可能覆盖外层同名)
scopeStack.push(name); // 记录插入操作
}
Binding lookup(string name) {
return symtab[name]; // O(1) 直接查表
}
void endScope() {
while (scopeStack.top() != SCOPE_MARKER) {
symtab.remove(scopeStack.top()); // 撤销该作用域内的所有插入
scopeStack.pop();
}
scopeStack.pop(); // 弹出 SCOPE_MARKER
}
过程示例:
beginScope() scopeStack=[◆]
insert("x", Ty_Int) scopeStack=[◆, "x"] symtab={"x": int}
insert("y", Ty_String) scopeStack=[◆, "x", "y"] symtab={"x": int, "y": string}
beginScope() scopeStack=[◆, "x", "y", ◆]
insert("x", Ty_Record) scopeStack=[..., ◆, "x"] symtab={"x": record, "y": string}
lookup("x") = record ← 找到内层 x (遮蔽外层)
endScope() pop "x" → 删除 x; pop ◆ → symtab={"x": int, "y": string}
lookup("x") = int ← 恢复外层 x
endScope() pop "y","x",◆ → symtab={}
复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
lookup |
\(O(1)\) | 哈希表直接查询 |
insert |
\(O(1)\) | 哈希表插入 + 栈压入 |
beginScope |
\(O(1)\) | 压入标记 |
endScope |
\(O(k)\) | \(k\) 为该作用域内的绑定数 |
优缺点:查找极快,但 endScope 需要逐条撤销、且多线程下需要同步。
4.2.3 Functional Implementation¶
核心思想:使用持久化数据结构 (Persistent Data Structure)——每次操作产生新表,旧表保持不变,新旧表共享大部分节点。
数据结构:平衡二叉搜索树 (如 AVL 树或红黑树),每个节点存 (key, value, left, right)。
使用路径复制技术:"复制从根节点到被插入节点的父节点的所有节点",从而可以避免完整拷贝所有旧版本,因此只有 \(O(\log(n))\) 的节点是多余的
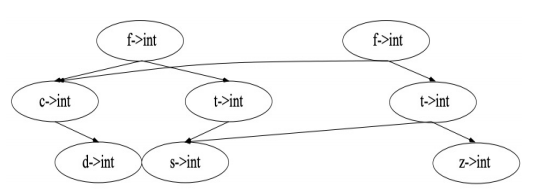
上面这个例子就是插入节点 z 的例子,插入到 t 的右边,于是复制相应的父亲节点
持久化操作:
hashTable insert(hashTable t, string name, Binding b) {
// 沿树路径创建新节点,O(log n)
// 返回新树的根,旧树 t 保持不变
}
Binding lookup(hashTable t, string name) {
// 标准 BST 查找,O(log n)
}
作用域管理:函数式实现的作用域管理极其简单——beginScope 直接返回当前表指针(不做任何修改),endScope 切换回进入前保存的旧表指针。
hashTable current = empty; // 当前环境
void beginScope() {
// 不需要做任何事 — 只需记住 current 指针
// 后续 insert 会创建新表,current 指向最新版本
}
hashTable saved = current; // 进入前保存
insert("x", Ty_Int); // current 指向新表
insert("y", Ty_String); // current 指向更新表
// ...
current = saved; // endScope: O(1) 恢复旧表
endScope 只需将 current 指回旧版本——旧版本仍然完好,O(1) 完成回退。
对比总结:
| 命令式 | 函数式 | |
|---|---|---|
| 核心数据结构 | 哈希表 + 栈 | 持久化 BST |
lookup |
\(O(1)\) | \(O(\log n)\) |
insert |
\(O(1)\) | \(O(\log n)\) |
endScope |
\(O(k)\) (逐条撤销) | \(O(1)\) (切换指针) |
| 多线程 | 需要同步 | 天然线程安全 |
| 内存 | 紧凑 | 路径复制,额外开销 |
4.2.4 Scope and Shadowing¶
遮蔽规则 (Shadowing):内层作用域声明的变量会覆盖外层同名的可见性。
let
var x := 5 // 外层 x: int
in
let
var x := "hello" // 内层 x: string — 遮蔽外层 x
in
print(x) // 引用内层 x, 类型为 string
end;
print(x) // 引用外层 x, 类型为 int
end
实现遮蔽的关键:insert 时新绑定覆盖旧绑定的表项(命令式中直接覆写哈希表;函数式中新节点在查找路径上先被找到),lookup 天然返回最新(最近作用域)的绑定。退出作用域时旧绑定自动恢复。
4.3 Type System¶
类型系统为程序中的值赋予分类标签(类型),并根据这些分类定义合法的操作组合。
4.3.1 Purpose of Types¶
| 维度 | 说明 | 示例 |
|---|---|---|
| 开发效率 | 高层抽象,IDE 自动补全和 API 搜索 | Haskell 的 Hoogle: 按类型签名搜索函数 |
| 运行性能 | 静态绑定消除运行时类型检查,优化内存布局 | C 的结构体字段偏移在编译时确定 |
| 安全可靠 | 内存安全、功能正确性 | Rust 的所有权系统防悬垂指针;Refinement Types 约束取值范围 |
静态 vs 动态类型检查:
| 静态检查 | 动态检查 | |
|---|---|---|
| 检查时机 | 编译时 | 运行时 |
| 典型语言 | C, Java, Rust, Haskell | Python, JavaScript, Ruby |
| 优点 | 提前发现错误,无运行时开销 | 灵活,开发快捷 |
| 缺点 | 类型标注繁琐 | 运行时错误,性能开销 |
Tiger 采用静态类型检查。
4.3.2 Tiger Type System¶
Tiger 语言的类型层次:
Ty
├── Ty_Int // 整型
├── Ty_String // 字符串
├── Ty_Record // 记录类型 {field1: type1, field2: type2, ...}
├── Ty_Array // 数组类型 array of type (元素类型存储为成员)
├── Ty_Name // 具名类型别名 (解析后指向上述某具体类型)
├── Ty_Nil // nil 类型 (兼容所有记录类型)
└── Ty_Void // 无返回值类型 (语句/过程的返回值)
基本类型:
- int:32 位有符号整数。比较运算(=, <>, <, <=, >, >=)返回 int(0 假,非 0 真)。
- string:字符串字面量。仅支持比较运算,无拼接操作。
构造类型:
- Record:{field1: type1, field2: type2, ...}。字段顺序敏感({x:int, y:int} 与 {y:int, x:int} 不同)。通过 . 访问字段。
- Array:array of element_type。通过 [index] 访问元素,索引必须是 int 表达式。
特殊类型:
- nil:空引用,兼容所有记录类型。nil 可以赋值给任何记录类型变量,也可以与任何记录类型比较。但不能赋给 int 或 string。
- void:不产生值的表达式(如 while、for、赋值语句、if 无 else 分支)的类型。
4.3.3 Type Equivalence¶
名字等价 (Name Equivalence):两个类型等价,当且仅当它们由同一次类型声明定义。
结构等价 (Structural Equivalence):两个类型等价,当且仅当它们具有相同的结构(递归展开到基本类型)。
Tiger 采用名字等价。
type a = {x: int, y: int}
type b = {x: int, y: int} // a 和 b 名字不同 → 不等价 !
type c = a // c 是 a 的别名 → c 和 a 等价
var va : a := nil
var vb : b := nil
va := vb // 类型错误! a ≠ b (名字等价)
var vc : c := nil
va := vc // 正确! a = c (同源声明)
Why Name Equivalence?
名字等价实现简单(直接比较类型名或声明标识),并防止"偶然结构相同但语义不同"的类型混用。例如 type Dollars = int 和 type Pounds = int 在名字等价下是不同类型,可防止货币单位混淆。缺点是需要显式类型声明。
等价性判定算法:对名字等价,只需将类型声明展开为"原始类型"后比较。实现中维护一个类型环境 tenv,Ty_Name(symbol) 在 tenv 中查找得到实际类型,递归解开直至非 Ty_Name。
4.3.4 Recursive Types¶
Tiger 中类型可以递归引用自身,但必须通过 record 或 array 间接进行:
type list = {head: int, tail: list} // ✓ 通过 record 递归
type tree = array of tree // ✓ 通过 array 递归
type a = a // ✗ 直接递归 (Tiger 不允许)
区分"递归类型"和"单纯引用别名":
- 递归类型:类型体内部直接或间接通过 record/array 引用自身,如
type list = {head: int, tail: list}——list的体部包含list本身。这是合法的递归类型,因为 record/array 在 Tiger 中是引用语义(存的是指针),大小固定。 - 单纯引用:
type b = a只是给已有类型起别名,b的体部不包含b自身——b和a指向同一个类型,没有产生新结构。
type list = {head: int, tail: list} // 递归类型 ✓ — 体部通过 record 引用自身
type tree = array of tree // 递归类型 ✓ — 体部通过 array 引用自身
type a = a // 直接递归 ✗ — 无限展开,无法确定大小
type b = c // 单纯引用 (别名) — b 只是 c 的别名
type c = {x: int} //
Forward Reference
相互引用的类型声明(如 type a = b; type b = {x: a})需要两遍扫描处理前向引用问题:第一遍预注册所有类型名作为占位符,第二遍在完整的名字环境下解析体部。
4.4 Type Checking: Formalization & Implementation¶
类型检查的核心是:在给定类型环境 \(\Gamma\) 下,推导表达式 \(e\) 的类型 \(\tau\)。
4.4.1 Formal System¶
类型环境 (Type Environment):
将变量名映射到其类型。
类型判断 (Type Judgment):
读作:"在环境 \(\Gamma\) 下,表达式 \(e\) 的类型是 \(\tau\)"。
推导规则 (Typing Rules) 以自然演绎风格书写——横线上方是前提,下方是结论:
基本规则:
Γ(x) = τ
(T-Int) ─────────── (T-Var) ────────── (T-String) ───────────────
Γ ⊢ n : int Γ ⊢ x : τ Γ ⊢ "s" : string
二元运算:
-, *, / 规则相同,要求左右操作数均为 int,结果也是 int。
比较运算:
Γ ⊢ e₁ : int Γ ⊢ e₂ : int
(T-Eq) ────────────────────────────────── // Tiger 中比较返回 0/1 (int)
Γ ⊢ e₁ = e₂ : int
Tiger 允许对 record 和 array 也使用 = 和 <>(地址比较),对 string 也允许比较(内容比较)。
控制流:
Γ ⊢ e₁ : int Γ ⊢ e₂ : τ Γ ⊢ e₃ : τ
(T-If) ─────────────────────────────────────────
Γ ⊢ if e₁ then e₂ else e₃ : τ
要求:条件必须是 int,then/else 分支类型相同。若其中一个分支是 nil,另一个是某个 record 类型 \(R\),则整体类型为 \(R\)。
while 和 for 循环始终具有 void 类型(不产生值)。
变量绑定:
其中 \(Γ \oplus Γ'\) 表示用 \(\Gamma'\) 扩展 \(\Gamma\)(新绑定覆盖同名旧绑定)。先处理声明块得到新的类型绑定 \(\Gamma'\),再在扩展后的环境中检查表达式体。
赋值语句类型为 void,左侧必须是可被赋值的左值(变量、记录字段、数组元素),左右类型必须匹配。
Record 与 Array:
Γ ⊢ e₁ : τ₁ ... Γ ⊢ eₙ : τₙ
(T-Record) ───────────────────────────────────
Γ ⊢ rectype{a₁=e₁, ..., aₙ=eₙ} : rectype
nil 兼容所有 record 类型:
函数调用:
Γ ⊢ f : (τ₁, τ₂, ..., τₙ) → τᵣ Γ ⊢ e₁ : τ₁ ... Γ ⊢ eₙ : τₙ
(T-Call) ──────────────────────────────────────────────────────────────────
Γ ⊢ f(e₁, ..., eₙ) : τᵣ
参数数量必须匹配,各参数类型必须一致。
序列表达式:
或用 Tiger 语法 e₁; e₂,整个表达式类型为第二个子表达式的类型。
4.4.2 Implementation Framework¶
类型检查器在 AST 上递归下降,类型信息自底向上流动。
环境维护:需要维护两个环境表:
venv(Variable Environment):变量名 → 类型。处理var声明、let表达式、函数形参时扩展,退出作用域时恢复。tenv(Type Environment):类型名 → 实际类型。处理type声明时扩展。
核心函数——以表达式类型检查为例:
Type transExp(ExpNode* e, Env* venv, Env* tenv) {
switch (e->kind) {
case INT: return Ty_Int;
case STRING: return Ty_String;
case VAR:
return lookup(venv, e->name); // 未找到 → 报错
case PLUS:
Type lt = transExp(e->left, venv, tenv);
Type rt = transExp(e->right, venv, tenv);
if (lt != Ty_Int || rt != Ty_Int)
error("+ requires int operands");
return Ty_Int;
case IF:
Type cond = transExp(e->cond, venv, tenv);
if (cond != Ty_Int) error("if condition must be int");
Type then = transExp(e->then, venv, tenv);
Type els = transExp(e->els, venv, tenv);
if (then != els) {
// 特殊处理 nil: nil 可匹配任意 record
if (isNil(then) && isRecord(els)) return els;
if (isNil(els) && isRecord(then)) return then;
error("if branches have different types");
}
return then;
case LET:
Env* saved = venv;
transDecs(e->decs, venv, tenv); // 处理声明,扩展 venv/tenv
Type body = transExp(e->body, venv, tenv);
venv = saved; // 恢复变量环境
return body;
case CALL:
Type func = lookup(venv, e->func);
// 检查参数数量和类型...
return func->result;
// ... 其余节点类型
}
}
错误恢复 (Error Recovery):类型检查过程中遇到错误(如未定义变量、类型不匹配)时,不终止检查——而是返回一个特殊类型(如 Ty_Int)或错误类型 Ty_Error,让检查器能继续处理剩余代码。这防止了级联报错(一个未定义变量导致后续所有使用该变量的表达式都报"类型错误")。
case VAR:
if (!exists(venv, e->name)) {
error("undefined variable: %s", e->name);
return Ty_Int; // 返回默认类型,继续检查
}
return lookup(venv, e->name);
4.4.3 Complete Example¶
以 Tiger 表达式为例,逐步展示类型推导过程:
let
type point = {x: int, y: int}
var p : point := point{x = 10, y = 20}
var d : int := p.x + p.y
in
if d > 0 then d else 0
end
类型环境初始化:\(\Gamma_{venv} = \{\}\), \(\Gamma_{tenv} = \{\}\)
Step 1 — 处理 type point = {x: int, y: int}:
- 体部 {x: int, y: int} 不引用 point 自身,不是递归类型,直接解析为 Ty_Record([("x", Ty_Int), ("y", Ty_Int)])
- point 加入 tenv,指向该 record 类型
Step 2 — 处理 var p : point := point{x = 10, y = 20}:
- 检查声明类型 point 在 tenv 中存在 → 解析为 record 类型
- 检查初始化表达式 point{x=10, y=20}:10 是 int 匹配字段 x: int ✓;20 是 int 匹配字段 y: int ✓
- 表达式类型为 point,与声明的 point 匹配 ✓
- \(\Gamma_{venv} = \{p : \text{point}\}\)
Step 3 — 处理 var d : int := p.x + p.y:
- 检查 p.x:p 类型为 point(record),字段 x 类型为 int → p.x : int ✓
- 检查 p.y:同理 → p.y : int ✓
- 检查 +:int + int → int ✓
- 声明类型 int 匹配初始化表达式类型 int ✓
- \(\Gamma_{venv} = \{p : \text{point},\; d : \text{int}\}\)
Step 4 — 检查表达式体 if d > 0 then d else 0:
Γ ⊢ d : int Γ ⊢ 0 : int
─────────────────────────── (T-Gt)
Γ ⊢ d > 0 : int Γ ⊢ d : int Γ ⊢ 0 : int
───────────────────────────────────────────────────────────────────────── (T-If)
Γ ⊢ if d > 0 then d else 0 : int
条件 \(d > 0\) 推导为 int ✓;then 分支 \(d\) 为 int,else 分支 \(0\) 为 int,两者一致 ✓。
Step 5 — 整体类型:let ... in ... end 体部类型为 int,整体表达式类型为 int ✓。
类型检查通过,无错误。
Comparison¶
| 名字解析 | 类型检查 | 作用域管理 | |
|---|---|---|---|
| 输入 | AST 中的标识符引用 | AST 中的表达式节点 | 块结构(let/函数体) |
| 核心结构 | 符号表 (名字 → 绑定) | 类型环境 (Γ) + 推导规则 | 作用域栈 / 持久化表 |
| 输出 | 每个引用指向其声明 | 每个表达式标注类型 | 局部变量在退出时失效 |
| 关键算法 | 递归遍历 + lookup | 递归遍历 + 自底向上类型推导 | beginScope/endScope |
| 典型错误 | 未定义变量、重复声明 | 类型不匹配、操作数类型错误 | — |
语义分析的核心思想可以概括为:在 AST 上递归遍历,用符号表维护作用域环境,用类型推导规则自底向上计算每个子表达式的类型,并在此过程中检查类型一致性。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!