10 Register Allocation¶
编译器后端将 IR 中的虚拟寄存器映射到物理寄存器。物理寄存器数量有限(通常 \(K \approx 16 \sim 32\)),无法容纳时部分变量必须溢出 (Spill) 到栈上。目标是最小化 load/store 开销。
核心问题是图着色——将干涉图中每个节点分配一种颜色(寄存器),相邻节点不能同色。图着色是 NP-Complete,实际编译器使用启发式算法,最经典的是 Chaitin-Briggs 图着色分配器。整个过程是循环迭代的:构建干涉图 → 简化/合并 → 着色 → 有溢出则重写后重新开始。
前置知识
依赖活跃变量分析的结果(def/use、生存期、干涉关系),详见第九章
10.1 Build¶
将程序转化为干涉图。节点代表虚拟寄存器(变量生存期),边表示两个变量生存期重叠(干涉)。与某节点相连的干涉边数称为度数 (Degree)。
对于 MOVE 指令(如 a = b),不直接加干涉边,而是记录一条移动边 (Move Edge)——如果 a 和 b 最终分配到同一寄存器,这条 MOVE 可被消除(合并优化)。
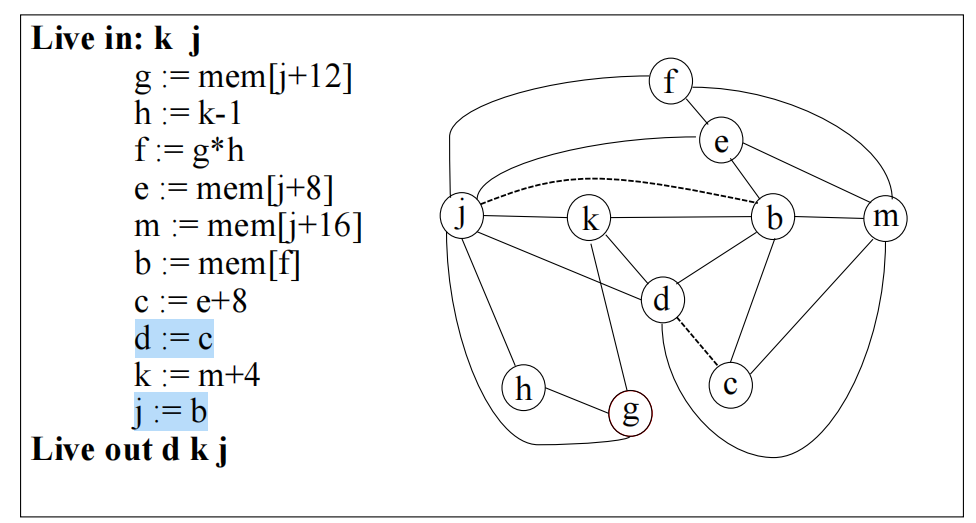
预着色节点 (Precolored Nodes):硬件寄存器(帧指针、参数寄存器等)作为预着色节点加入图中。它们之间互相干涉,度数视为无穷大(不能被简化或溢出)。
10.2 Simplify & Coalesce¶
这是算法核心的"收缩"循环。在图上反复执行以下操作,直到图为空或只剩高度数节点:
Simplify — 选取度数 \(< K\) 且不与任何 move edge 相连的节点,从图中移除并压入选择栈。原理来自 Kempe 定理:度数 \(< K\) 的节点永远可被着色(不管邻居最终分到什么颜色,至少一种颜色未被占用),因此可安全推迟着色决策。
Coalesce — 尝试合并由 move edge 连接的节点对 (u, v),消除 MOVE 指令。风险是合并后度数可能 \(\geq K\),导致原本可着色的图变为不可着色,因此需要保守合并策略:
Briggs 准则
合并 u 和 v 安全,当且仅当合并后新节点度数 \(\geq K\) 的邻居数 \(< K\)。直觉:只要高度数邻居少于 \(K\) 个,简化阶段仍能处理它。
George 准则
u(度数低的节点)的每个邻居要么已与 v 干涉,要么度数 \(< K\)。比 Briggs 更宽松但检查成本更高。
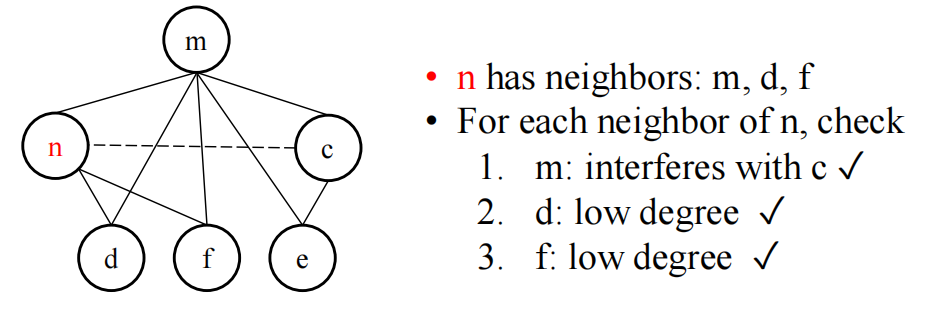
Freeze — 当无法简化也无法合并,但存在度数 \(< K\) 的移动相关节点时,放弃合并希望:将与其相连的 move edge 转为普通干涉边,使该节点有资格进入 Simplify。优先冻结度数最低的移动相关节点。
Potential Spill — 图中只剩下度数 \(\geq K\) 的节点时,选择溢出代价最低的节点,标记为潜在溢出,压栈并从图中移除,继续循环。溢出代价估算:
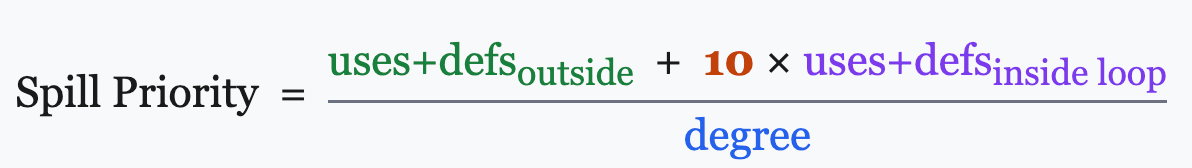
Example
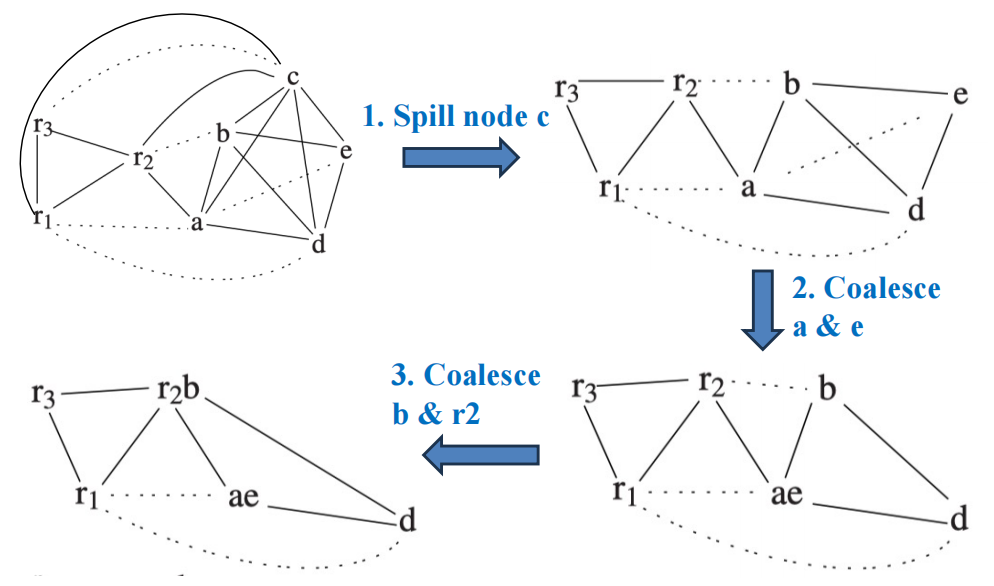
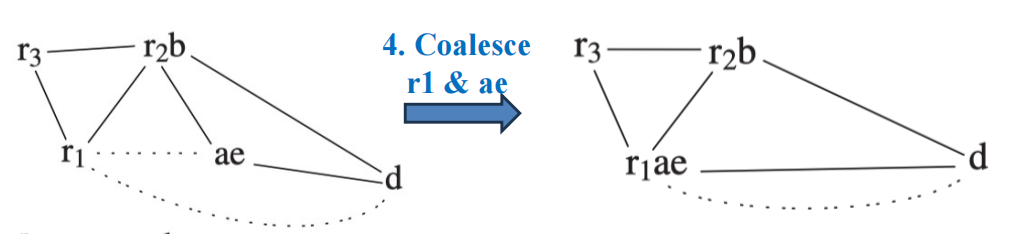
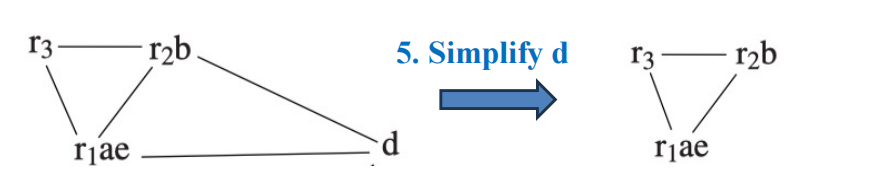
10.3 Select¶
图为空后,从选择栈顶弹出节点逐个着色。对每个节点,从 \(K\) 种颜色中选择一个未被已着色邻居占用的颜色。
潜在溢出节点采用乐观着色 (Optimistic Coloring):先尝试分配颜色,不成功才标记为实际溢出。Briggs 发现:某些潜在溢出节点在邻居着色后实际仍有可用颜色(邻居可能共享颜色),因此乐观着色显著减少不必要的溢出。
乐观着色
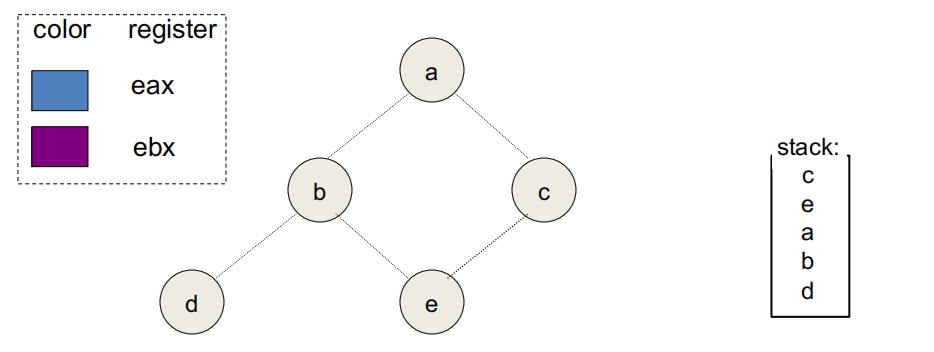
比如说上面这个情况就是 b 是 Potential Spill,但是实际着色的时候发现 a 和 e 是同一个,所以实际上 b 是可以着色的,不用溢出
10.4 Rewrite¶
若着色成功(无实际溢出),流程结束,替换虚拟寄存器为物理寄存器,删除被合并消除的 MOVE。
若有实际溢出,则为溢出变量在栈上分配空间:每次定义后插入 Store,每次使用前插入 Load。溢出后变量生存期被拆分为多个短生存期(每个 def/use 点变为独立临时变量),改变了干涉图。随后回到 Build 阶段重新运行整个流程。
溢出前: 溢出后:
a = ... a = ...
Store a → [sp+0]
b = a + 1 t1 = Load [sp+0]
b = t1 + 1
c = a + 2 t2 = Load [sp+0]
c = t2 + 2
Tiger book的寄存器分配中,是否可以一次性spill多个节点,还是说发现多个acctual spill后选一个每次只actual spill一个?
-
选“潜在 spill”时(第一个大步骤“Simplify”)——一次只选一个,用启发式的spilig cost
-
在select阶段可能累积得到多个 “actual spill”,但是其中一些可能因为Optimisc策略而不用针的do actual spill。
-
Select阶段最终可能剩下不止一个actal spill。 那么Rewrite——把所有 actual spill 一次性插入内存访问,再重跑整个分配器。
评论区
对你有帮助的话请给我个赞和 star => 欢迎跟我探讨!!!
欢迎跟我探讨!!!